

코딩 테스트 대비에 앞서 기본적인 자료 구조에 대해 학습하고자 한다.
자료 구조 설명에 앞서, 해당 자료(링크)를 한번씩 읽어봤으면 좋겠다. 자료 구조에 대한 인사이트를 제공하는 포스트다.
(자료 구조에 대한 원론적인 설명은 위 포스트로 대체한다.)
핵심 자료 구조

우리가 다룰 자료 구조는 자료형에 따라 크게 8개로 분류된다.
Primitive Data Structure
Primitive Data Structure은 프로그래밍에서 데이터를 저장하고 처리하는 가장 기본적인 형태의 구조를 의미한다. 이들은 프로그래밍 언어에 내장된 데이터 타입으로, 일반적으로 추가적인 추상화 없이 메모리에 직접적으로 저장되고 접근한다.
Primitive Data Structure은 Integer(정수형), Float(실수형), Character(문자형), Pointer(포인터)로 구성된다. 앞서 3개(Integer, Float, Character)는 익숙할 듯한데, Pointer에 대해서는 익숙하지 않을 수 있어 언급하고자 한다.
Pointer(포인터)는 Integer, Float, Character 처럼 그 자체로 정수, 실수, 문자처럼 의미있는 값을 갖지 않는다. 이게 무슨 말이냐면, Pointer는 컴퓨터 메모리 내에 자료가 저장된 메모리 주소를 통해 자료형의 실제 값을 불러낼 수 있다는 의미다.
NonPrimitive Data Structure
이 NonPrimitive Data Structure 자료구조는 위의 Primitive Data Structure을 응용한 자료구조라고 생각하면 된다.
여기서부터는 하나하나 자세히 뜯어보자.
Array(배열)
Array(배열)는 numpy를 사용해본 사람이라면 익숙한 자료구조일 것이다. Array의 경우 동일한 타입의 데이터들을 저장하며 고정된 크기를 가지고 있다. 그리고 각 원소에 대해 인덱싱이 되어 있어서 인덱스 번호로 데이터에 접근할 수 있다.
Array는 배열 목록, 힙, 해시 테이블, 벡터 및 행렬과 같은 기타 데이터 구조를 구축하기 위한 빌딩 블록으로 사용되며, 다양한 정렬 알고리즘에 사용된다.
Linked List(연결 리스트)
Linked List(연결 리스트)는 각 데이터 시퀸스가 순서를 가지고 연결된 순차적인 구조로 동적인 데이터 추가와 삭제에 유리한 데이터 구조이다.
각 데이터 시퀸스는 Node라고 하며, 각 Node에는 Key와 다음 노드를 가리키는 포인터인 Next가 포함되어 있는 구조다. 이때 데이터 시퀸스(Node)의 첫 번째 요소를 Head라고 하며 마지막 요소를 Tail이라고 한다.
Stack(스택)
스택의 경우는 Array의 구조인데 한쪽이 막힌 Array구조다. 때문에 순서가 보존되는 선형 데이터 구조로 분류가 된다. 아래 그림과 같이 가장 마지막에 추가된 요소, 즉 가장 최근에 추가된 요소부터 처리하는 LIFO 구조다.
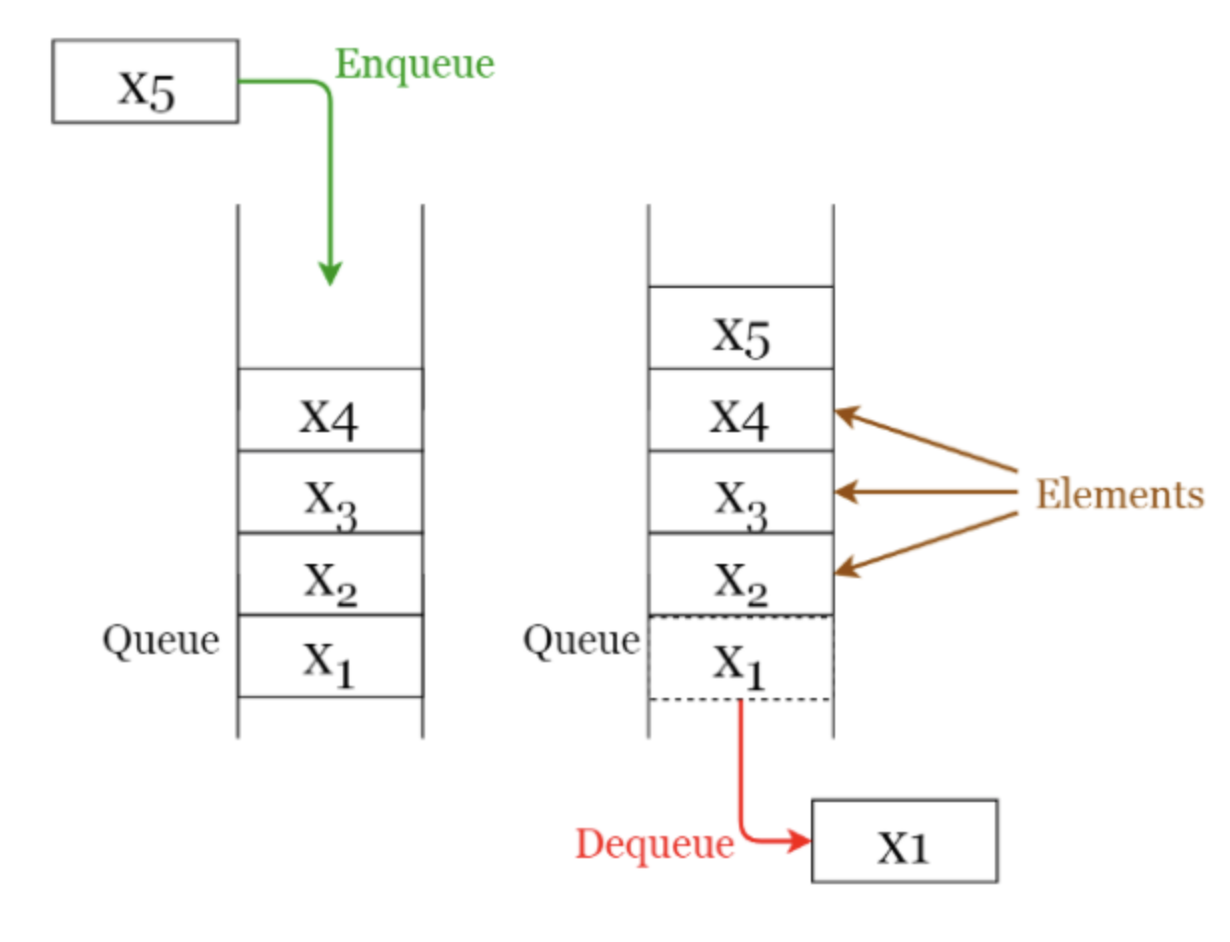
Queue(큐)
Queue(큐)의 경우도 Array구조를 기반으로 하며 이는 Stack과 달리 한쪽만 막힌 구조가 아닌 양쪽 다 뚫려있는 구조다. 때문에 가장 먼저 입력된 요소가 출력으로 나오게 되는 FIFO구조를 가지고 있는 것이 특징이다.
Hash Table(해시 테이블)
해시 테이블을 이해하기 위해서는 이전에 해시 함수에 대해 짚고 넘어갈 필요가 있다.
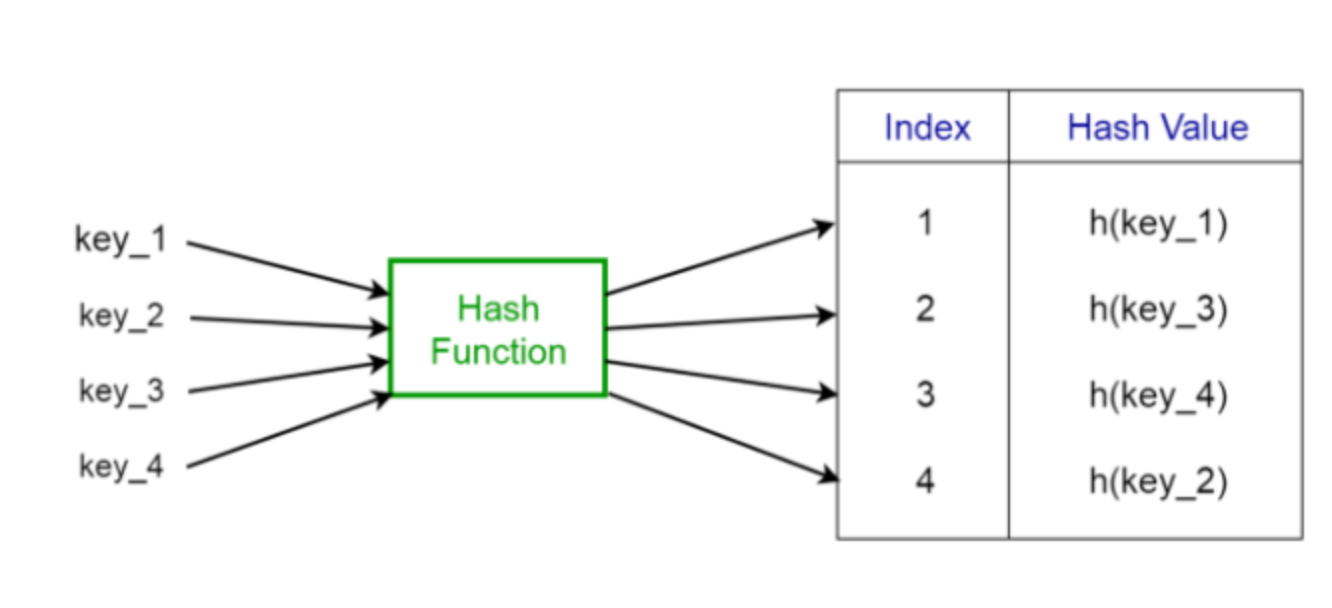
해시함수란 임의의 데이터(입력 데이터에 대한 제한은 없음)를 입력받아 일정한 길이의 비트열로 반환 시켜주는 함수다. 이때 입력값의 길이가 달라도 출력값은 언제나 고정된 길이로 반환하며 동일한 값이 입력되면 언제나 동일한 출력값을 보장하는 함수다.
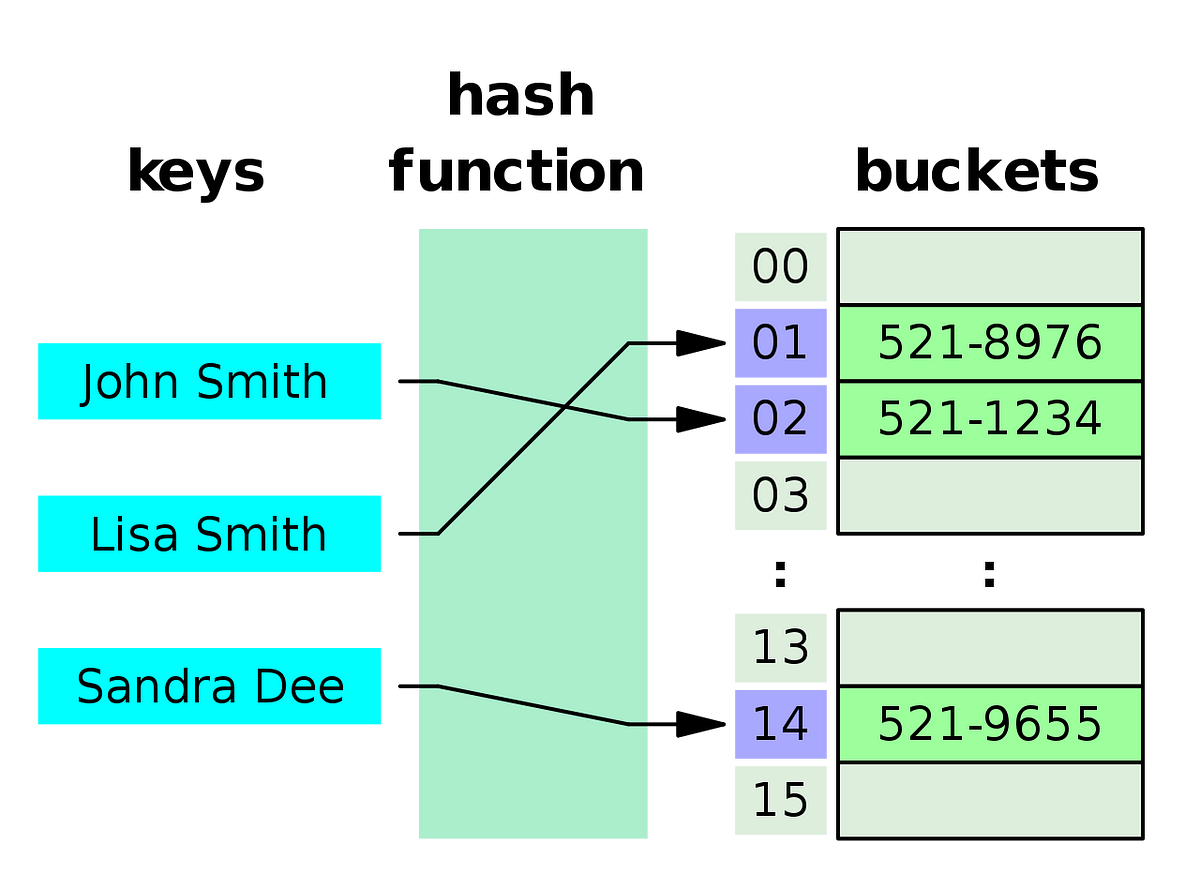
Hash Table(해시 테이블)의 경우 해시함수를 사용하여 변환한 값을 색인(index)로 삼아 Key와 Value를 저장하는 자료구조다. 해시함수의 특징과 동일하게 데이터의 크기에 관계없이 삽입과 검색에 매우 효율적이라는 장점을 가지고 있다.
Hash Table의 경우 보통 테이블 안에 작은 서브그룹인 bucket(버킷)과 Key/Value 쌍을 저장한다. 그러나, 충동이 자주 일어날 수 있다는 단점이 존재하며, 이를 위해 해시 함수를 개선하거나 해시 테이블의 구조 개선 등의 방법이 사용이 된다.
Graph(그래프)
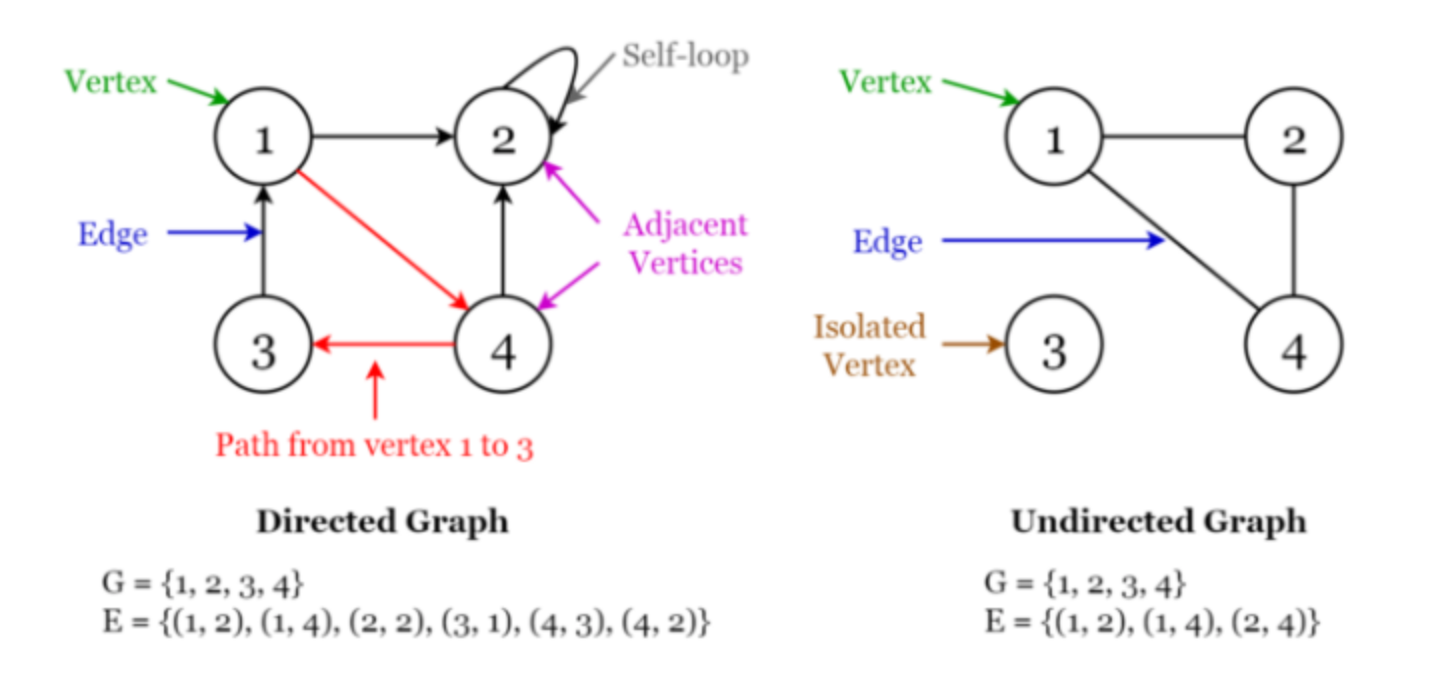
이전 GNN 피드에도 언급하였지만, Graph(그래프) 자료구조는 node와 Edge의 연결로 이루어진 자료구조다. 화살표가 존재하는 directed 그래프는 일방통행을 의미하며, 화살표가 존재하지 않고 선만 존재하는 undirected 그래프는 양방향을 의미한다.
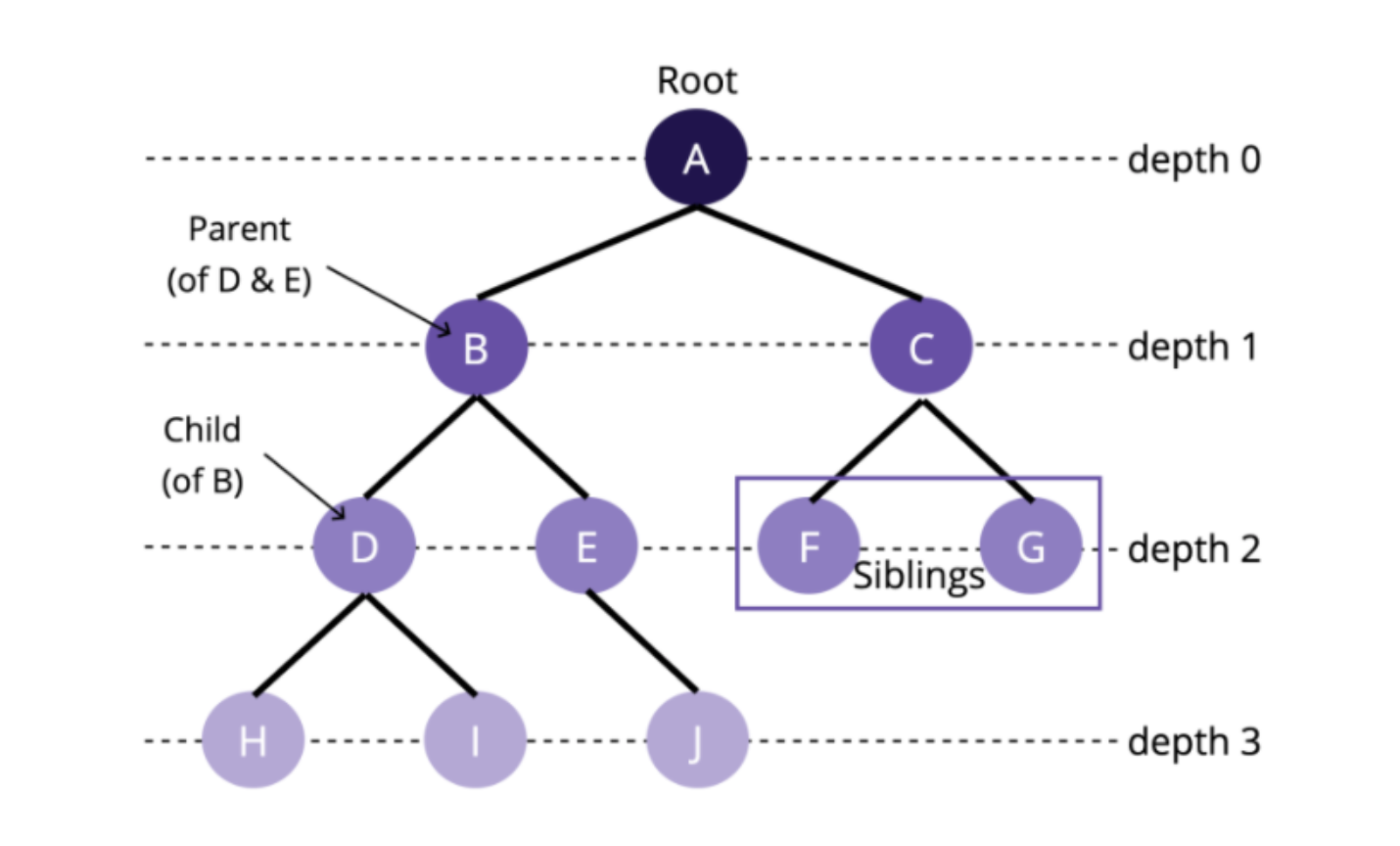
Tree(트리)
Tree(트리) 자료구조는 그래프가 계층적 구조를 가진 형태를 의미한다. Decision Tree 모델을 떠올리면 쉬울듯하다. 마찬가지로 최상의 노트(Root)를 가지고 있으며 상위 노드를 부모(Parent)노드 하위 노드를 자식(Child) 노드라고 한다.
Heap(힙)
Heap(힙) 자료구조는 우선순위 큐를 위해 고안된 완전 이진 트리 자료구조로 여러 값 중에 최대값과 최솟값을 빠르게 찾아내도록 만들어진 자료구조다. 힙은 부모 노드의 키 값이 자식 노드의 키 값보다 항상 크거나 작은 반정렬 상태를 유지하며 이진탐색트리와 달리 중복된 값이 허용이 된다.
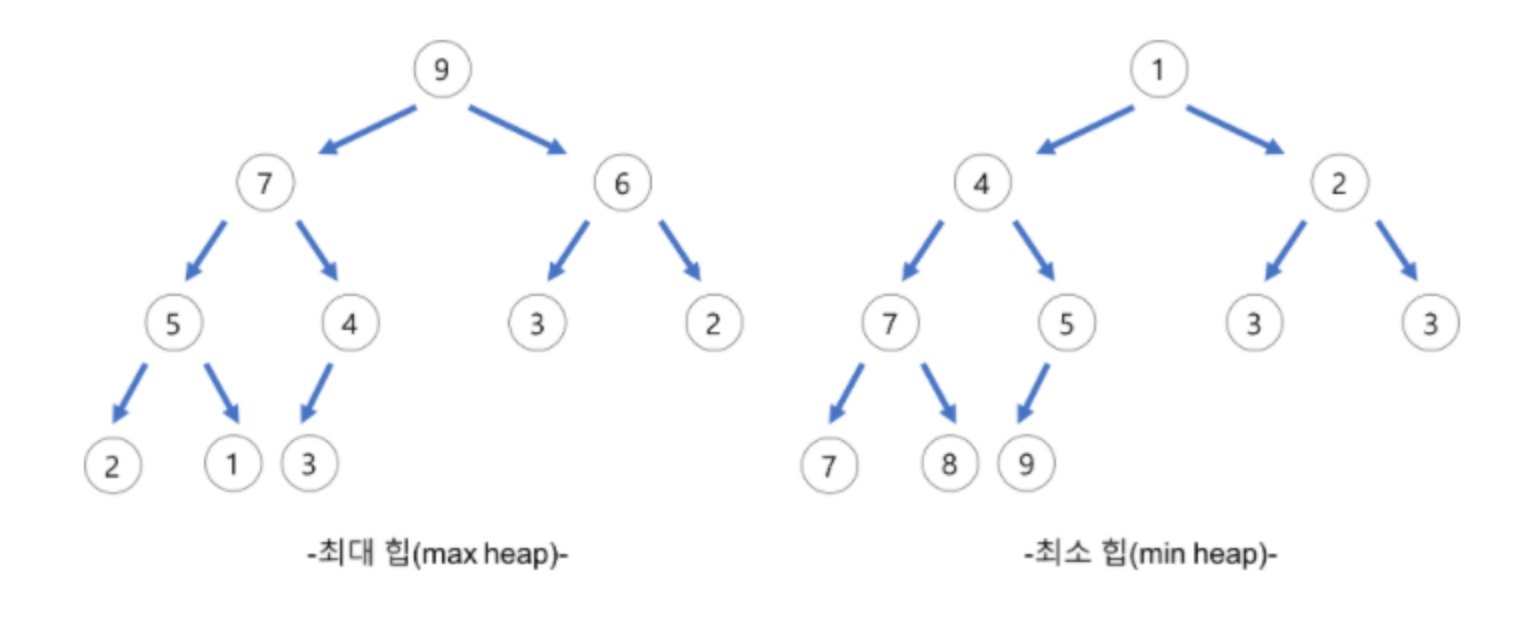
힙의 종류는 최소 Heap과 최대 Heap으로 나뉘는데, 최소 Heap의 경우 부모의 Key값이 자식의 키 값보다 작거나 같은 구조를 의미한다. 즉, 루트 노드의 Key 값이 트리의 최솟값이다. 최대 Heap의 경우 부모의 키 값이 자식의 Key값보다 크거나 같다. 이때 루트 노드의 Key값이 트리의 최대값이다.
Reference
https://bnzn2426.tistory.com/115
자료 구조(Data Structure) 개념 및 종류 정리
자료 구조란? 데이터 값의 모임, 각 원소들이 논리적으로 정의된 규칙에 의해 나열되며 자료에 대한 처리를 효율적으로 수행할 수 있도록 자료를 구분하여 표현한 것. 예를 들어 한정된 크기의
bnzn2426.tistory.com
https://lizable.github.io/datastructure/Introductions-to-data-structure/#description
[자료구조]1.1 Introductions to Data Structure
자료구조 정리를 시작하며
lizable.github.io
'Data Structure & Algorithm' 카테고리의 다른 글
| [Data Structure] Graph (3) | 2024.08.28 |
|---|---|
| [Algorithm] 시간 복잡도와 빅오(Big-O) 표기법 (1) | 2024.05.15 |