

오늘은 간단하게 CNN (Convolutional Neural Network)에 대해서 리뷰하고자 한다. CNN은 이미지 처리와 패턴 인식에 우수한 성능을 보여주는 신경망이다.
이미지는 픽셀로 이루어진 격자 형태의 데이터이다. 이미지는 픽셀로 이루어져 있고 각각의 픽셀은 RGB(Red, Green, Blue)값을 가진 데이터이다.

CNN은 이러한 이미지 데이터의 공간적인 특징을 추출하여 학습하고 이를 기반으로 패턴을 인식하는 데 사용된다.
이를 위해 CNN은 주로 합성곱 층(Convolutional layer), 풀링 층(Pooling layer), 밀집층(Fully-connected layer, Dense layer)으로 구성이 된다.
합성곱 층(Convolutional Layer)
합성곱 층(Convolutional Layer)은 CNN에서 이미지 처리와 패턴 인식을 위해 주로 사용이 되는 중요한 구성요소다. 합성곱 층은 입력 이미지와 작은 크기의 필터(Kernel) 간의 합성곱 연산을 통해서 새로운 특성 맵(Feature map)을 생성한다.
이를 통해 이미지의 지역적인 패턴을 감지하고 추출할 수 있다. 합성곱 연산은 커널과 이미지의 각 픽셀별로 곱하여 합산하는 과정을 의미한다. 아래와 같은 방법으로 커널을 이동해가면서 합성곱의 값을 구해준다.
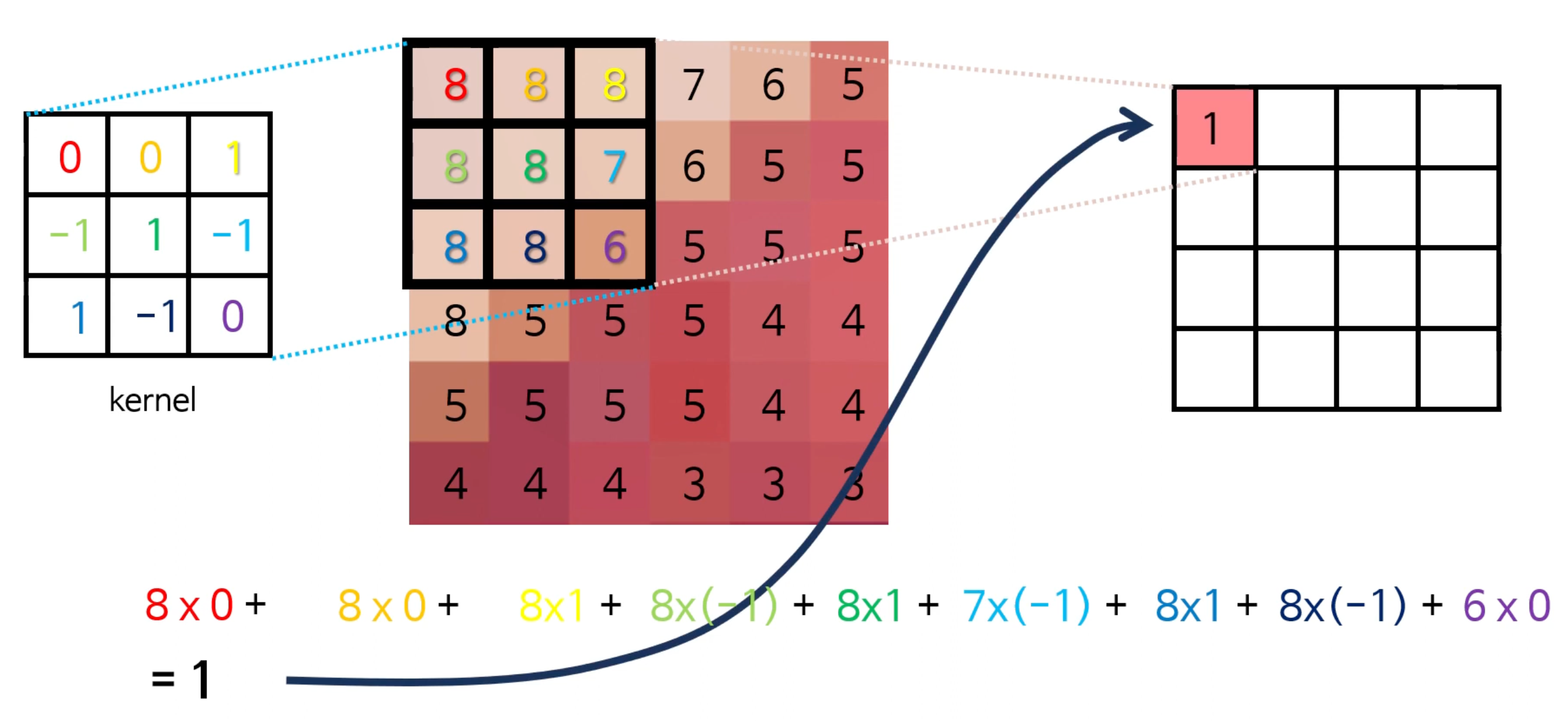
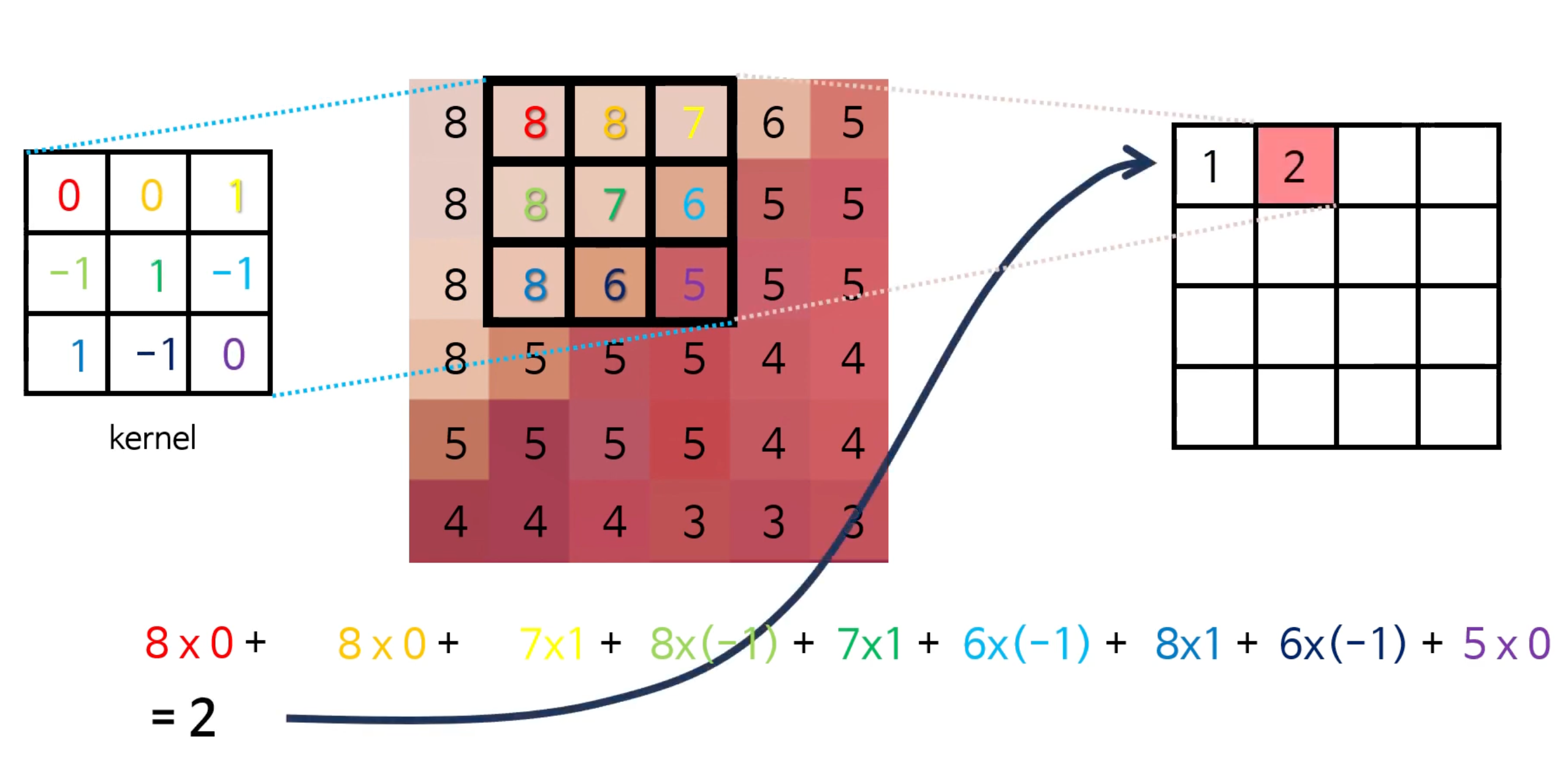
이렇게 계산된 결과를 모아서 새로운 특성 맵(Feature map)을 생성한다. 이것이 바로 합성곱 연산의 핵심이다!

그렇다면, 합성곱 연산이 갖는 의미는 무엇일까?
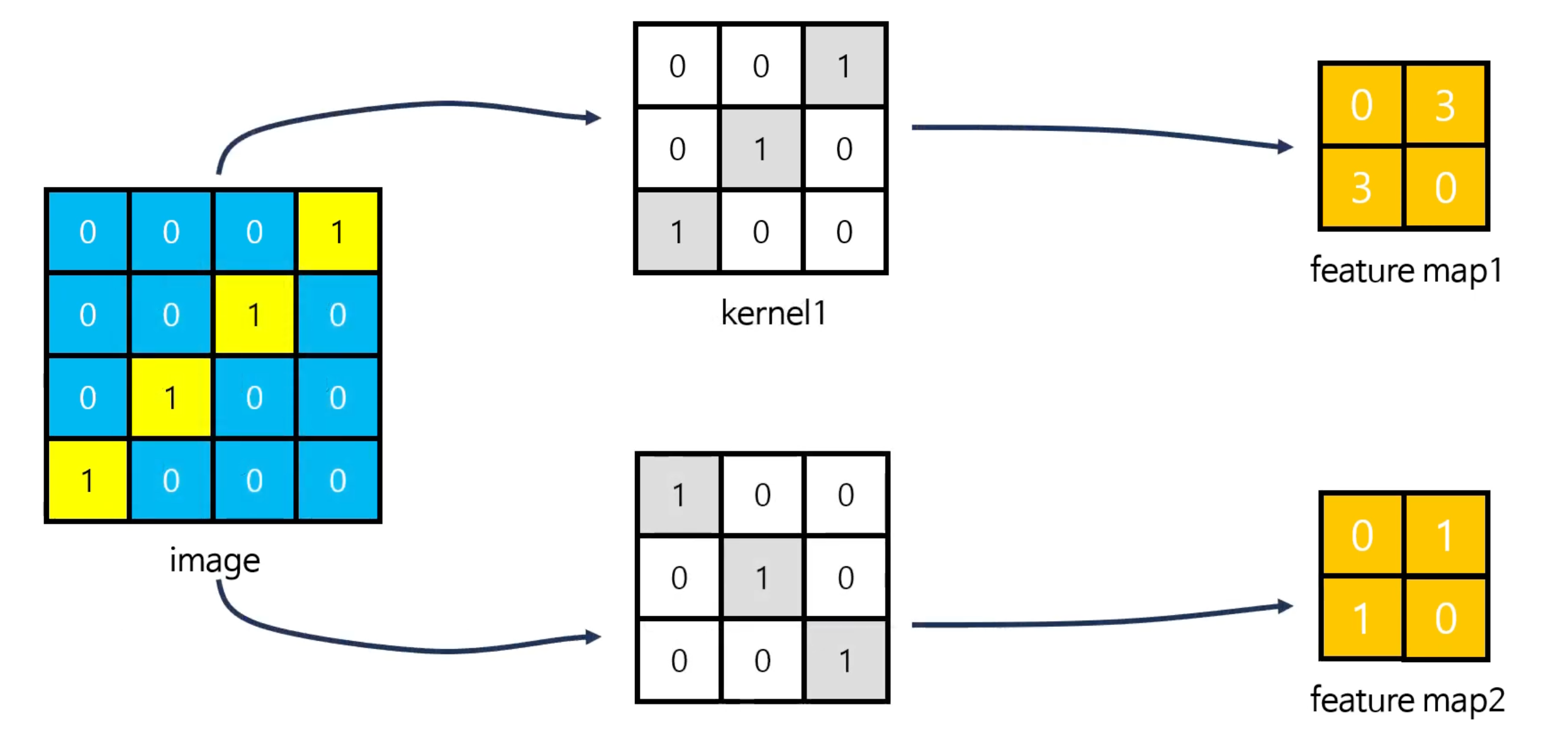
예를 들어서 아래와 같은 이미지와 커널이 있다고 가정해보자.
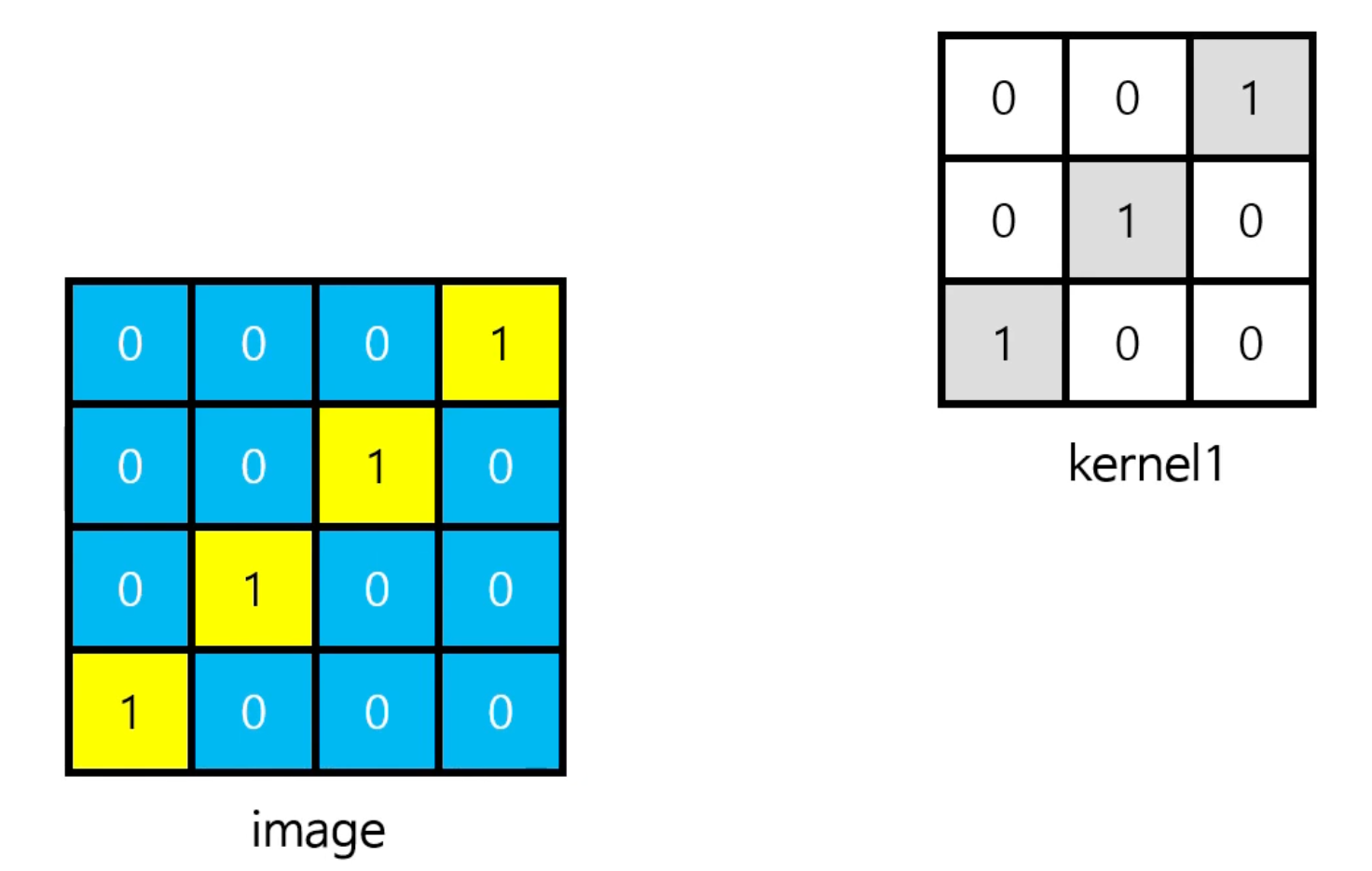
여기서 합성곱 연산을 수행하면, 아래와 같은 Feature map이 새로 만들어진다.
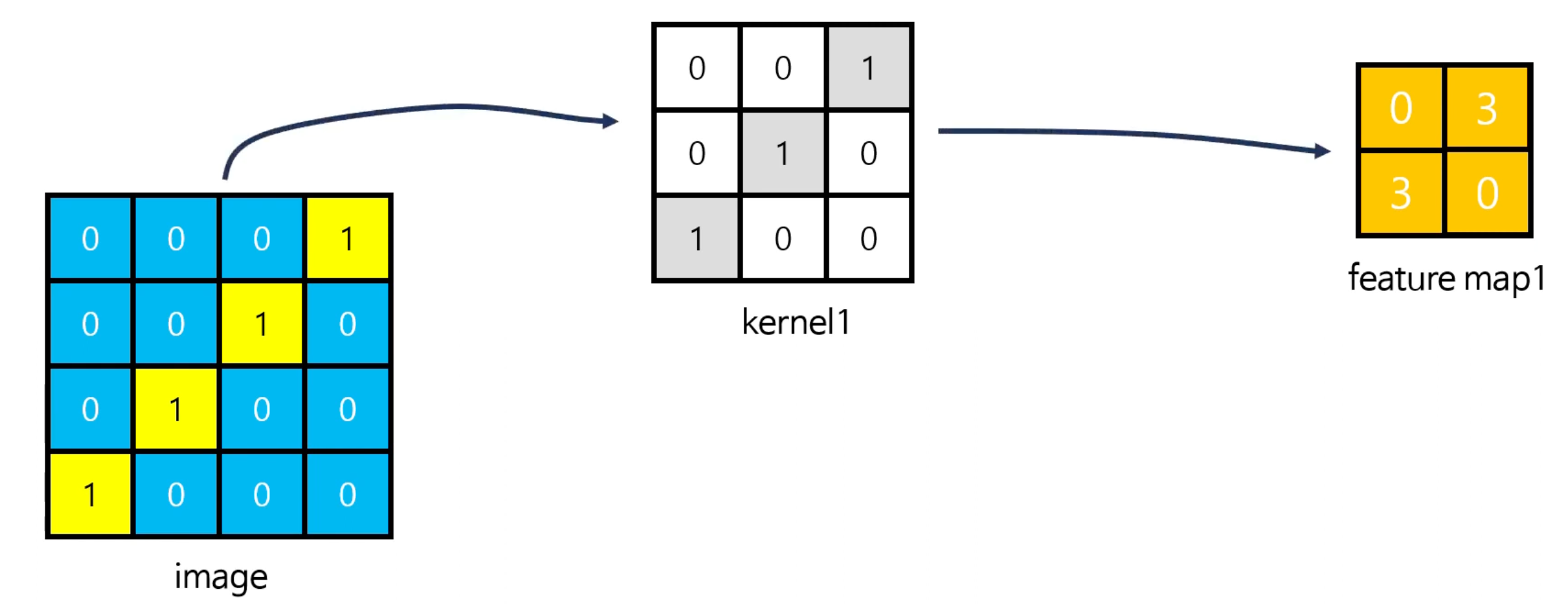
그렇다면 커널이 정반대인 모형은 어떨까? 예를 들면 아래와 같다. 여기서 주의깊게 보면, 이미지의 특성과 유사한 커널의 출력값이 높고 이미지 특성을 반영하지 않는 커널은 출력값이 상대적으로 낮음을 확인할 수 있다.
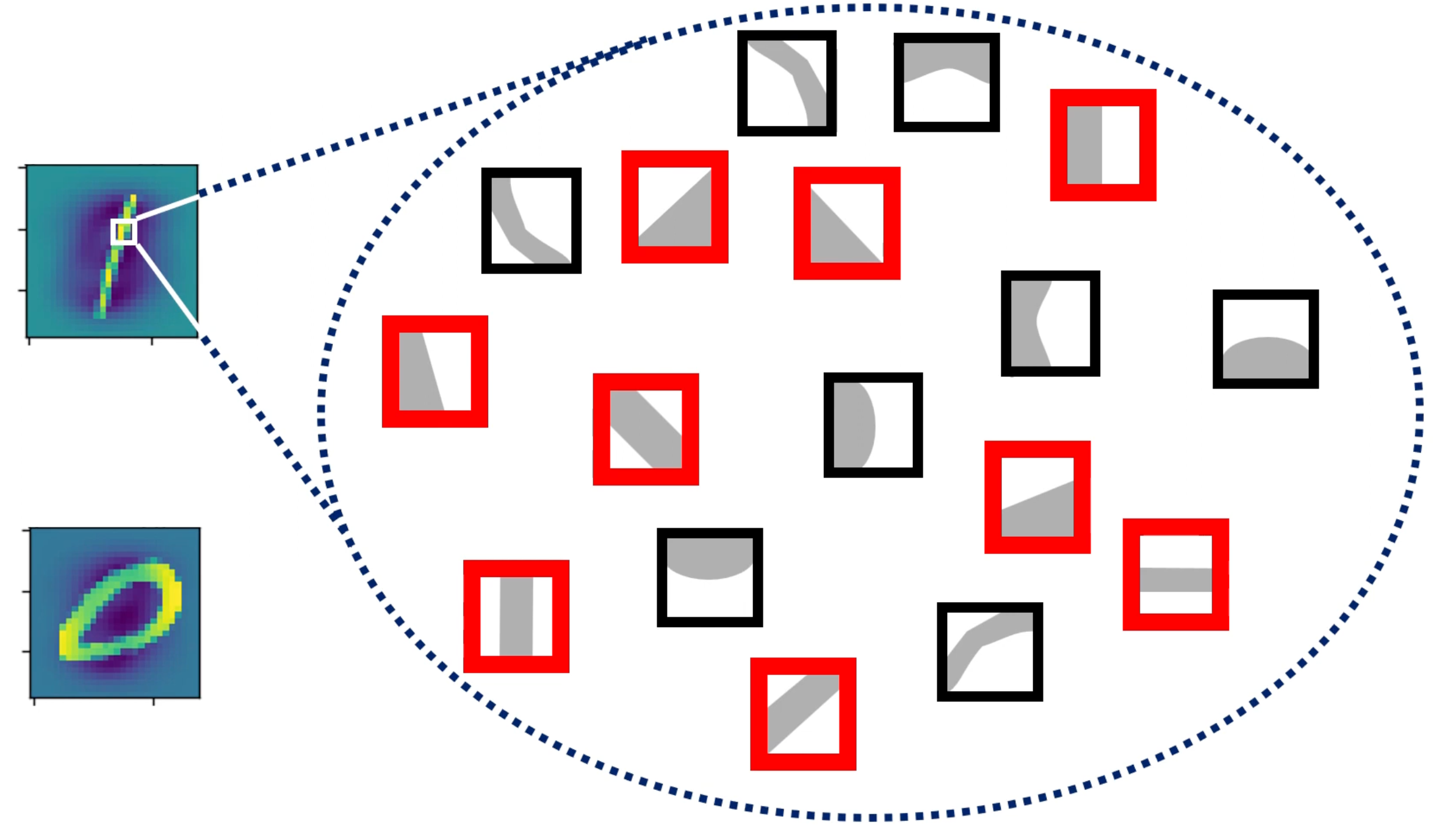
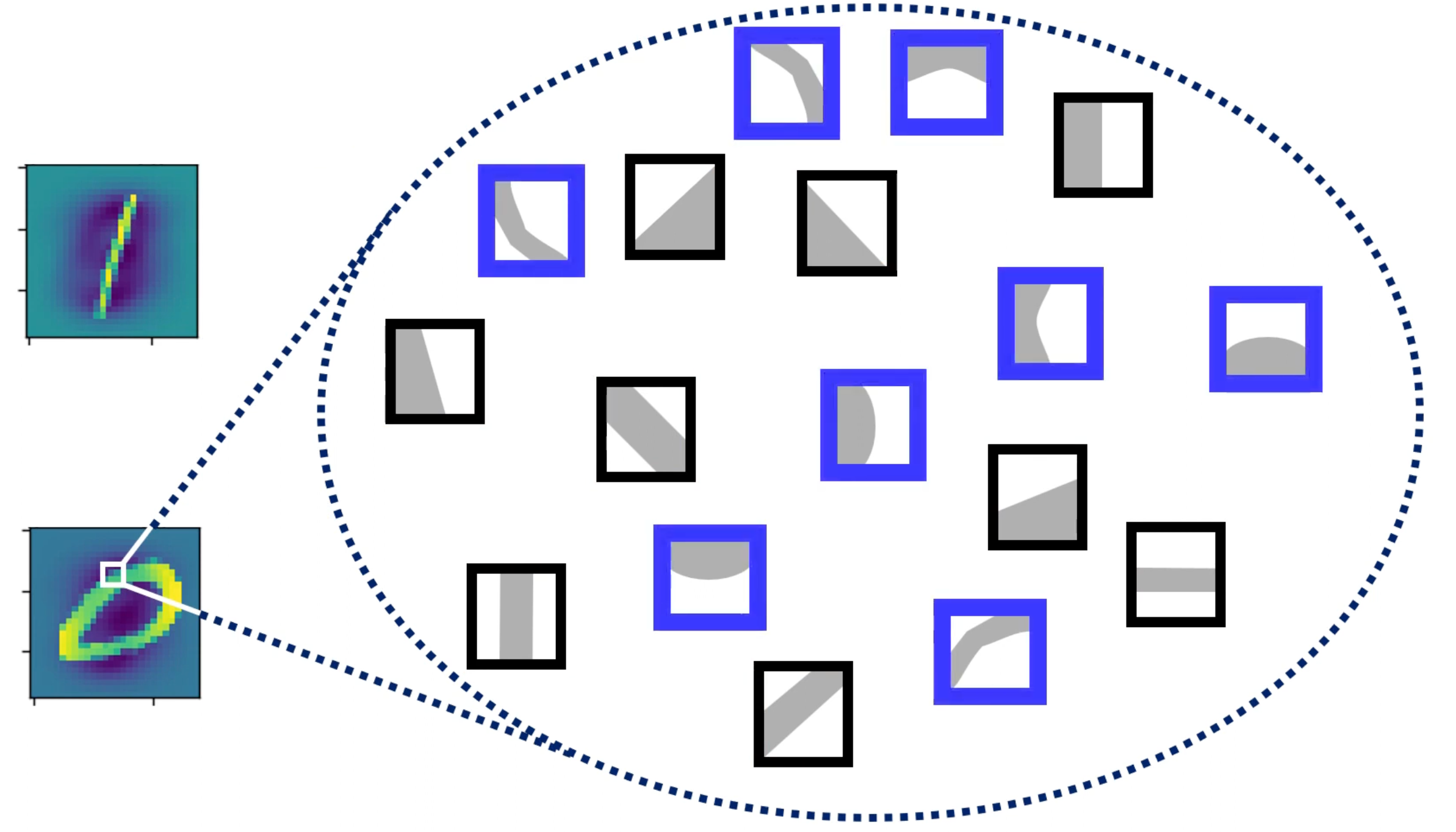
좀 더 확장하여 이 개념을 생각해본다면, 아래 사진과 같이 여러 종류의 kernel들이 존재한다고 가정해볼때, 1이라는 이미지가 입력이 될 경우엔 직선형태의 kernel들의 합성곱 출력값이 높아지고 0이라는 이미지가 입력될 경우엔 곡선 형태의 kernel들의 합성곱 출력값이 높아진다고 생각할 수 있다. 즉 합성곱 출력값을 일종의 확률이라고 생각해본다면, 합성곱 레이어의 역할은 주어진 이미지의 지역적 특성(Feature)을 분석하여 확률로 리턴하는 역할을 수행한다고 보면 된다.
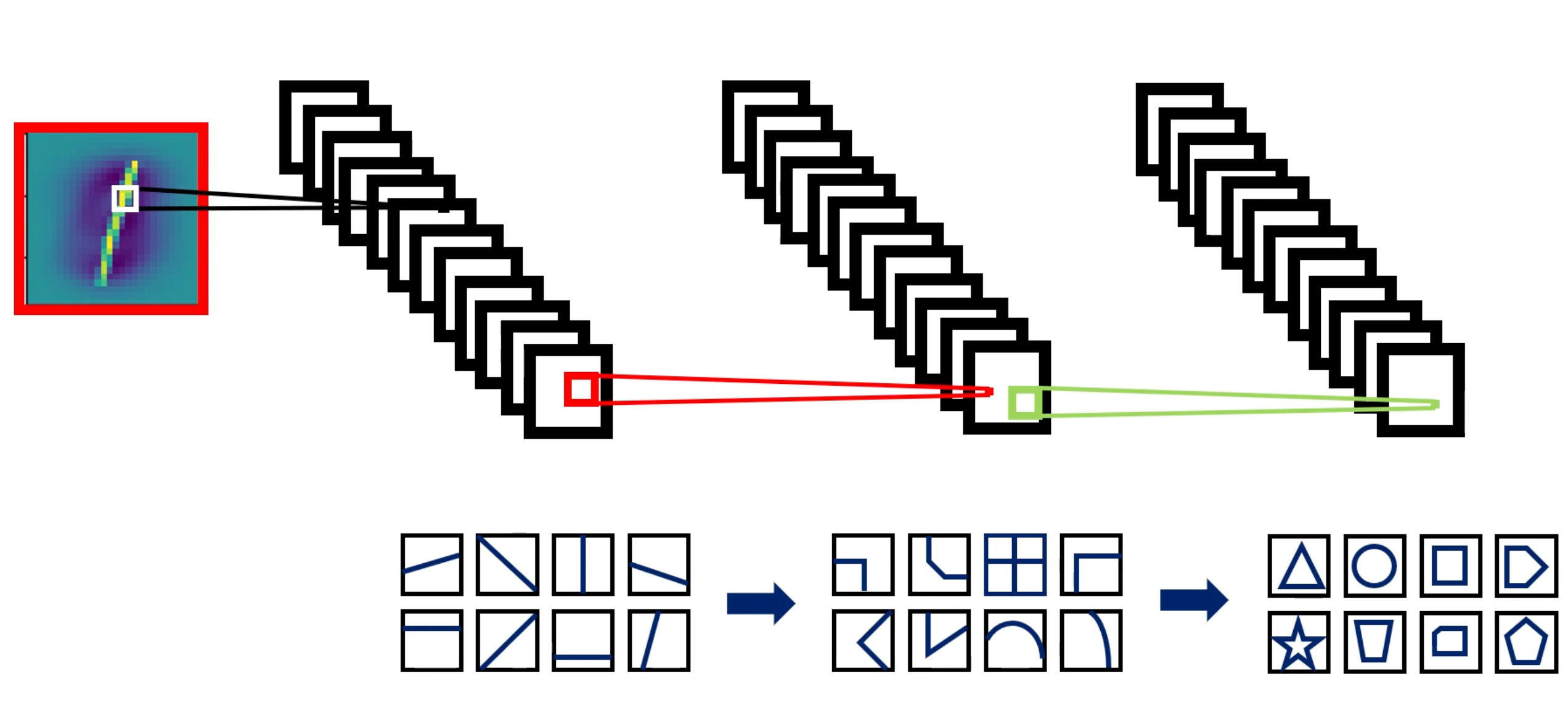
더불어 합성곱 층이 깊어질 수록, 더 복잡한 형태의 Local Feature도 처리할 수 있게 된다. (처음에는 단순한 직선 형태의 데이터 였다면, 나중에는 직선과 직선이 만나는 복잡한 형태, 더 복잡한 형태도 처리할 수 있게된다.) 그런 식으로 개와 고양이 같은 모형도 합성곱 층이 깊어지게 되면 이미지를 분류할 수 있게 되는 것이다.
kernel의 크기와 보폭(stride)은 합성곱 층의 출력층의 크기를 조절하는 중요한 요소이다. 아래와 같이 크기가 서로 다른 두개의 커널은 합성곱 연산을 마치고 나면 Feature map의 크기가 다르게 생성된다. Feature map의 크기가 다르다는 것은 층이 깊어질수록 Feature Map의 크기가 너무 크면 연산량이 너무 커지게 된다는 것을 의미한다. 따라서 Feature map의 크기가 너무 크지 않도록 해주는 것이 좋다. (Feature map의 크기가 크면 복잡한 이미지를 분류할 수 있겠지만, 너무 연산량이 많아서 학습이 오래걸린다는 단점이 존재함)
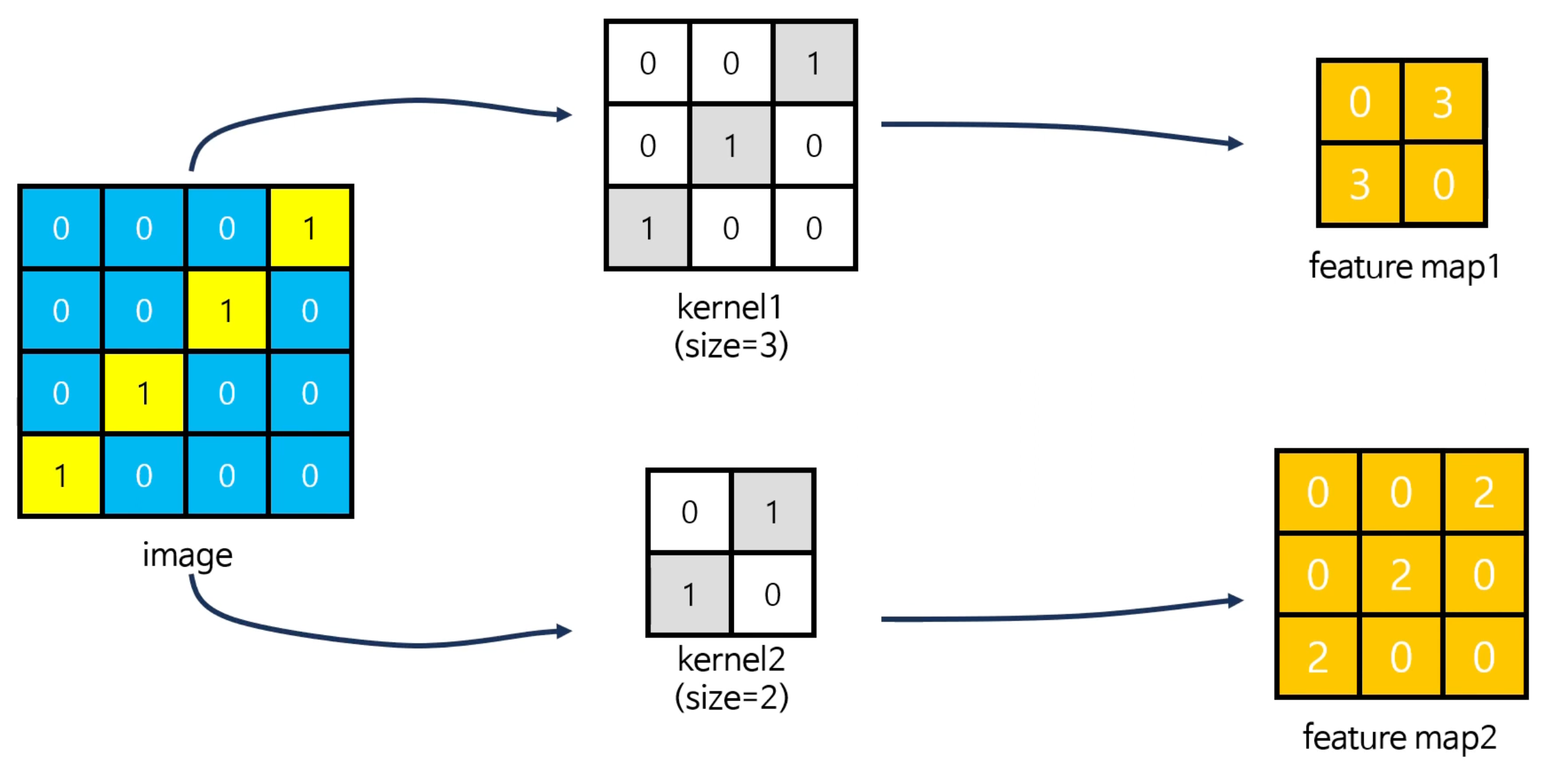
때문에 이미지의 픽셀수가 많을 수록 디테일한 이미지가 되는 것처럼 Feature map의 크기가 커질 수록 좀 더 디테일한 이미지의 특성을 잡아낼 수 있다는 장점이 있지만, 마찬가지로 연산량이 높아지기에 이러한 장단점을 고려하여 CNN의 모델을 만들어주는 것이 좋다. (=Feature map의 크기가 클수록 Feature의 디테일을 표현할 수 있다. 그러므로 kernel의 사이즈가 작으면 디테일한 feature도 처리할 수 있게 되지만, 그만큼 연산량도 증가하기 때문에 적절한 크기를 찾는 것이 중요하다.)
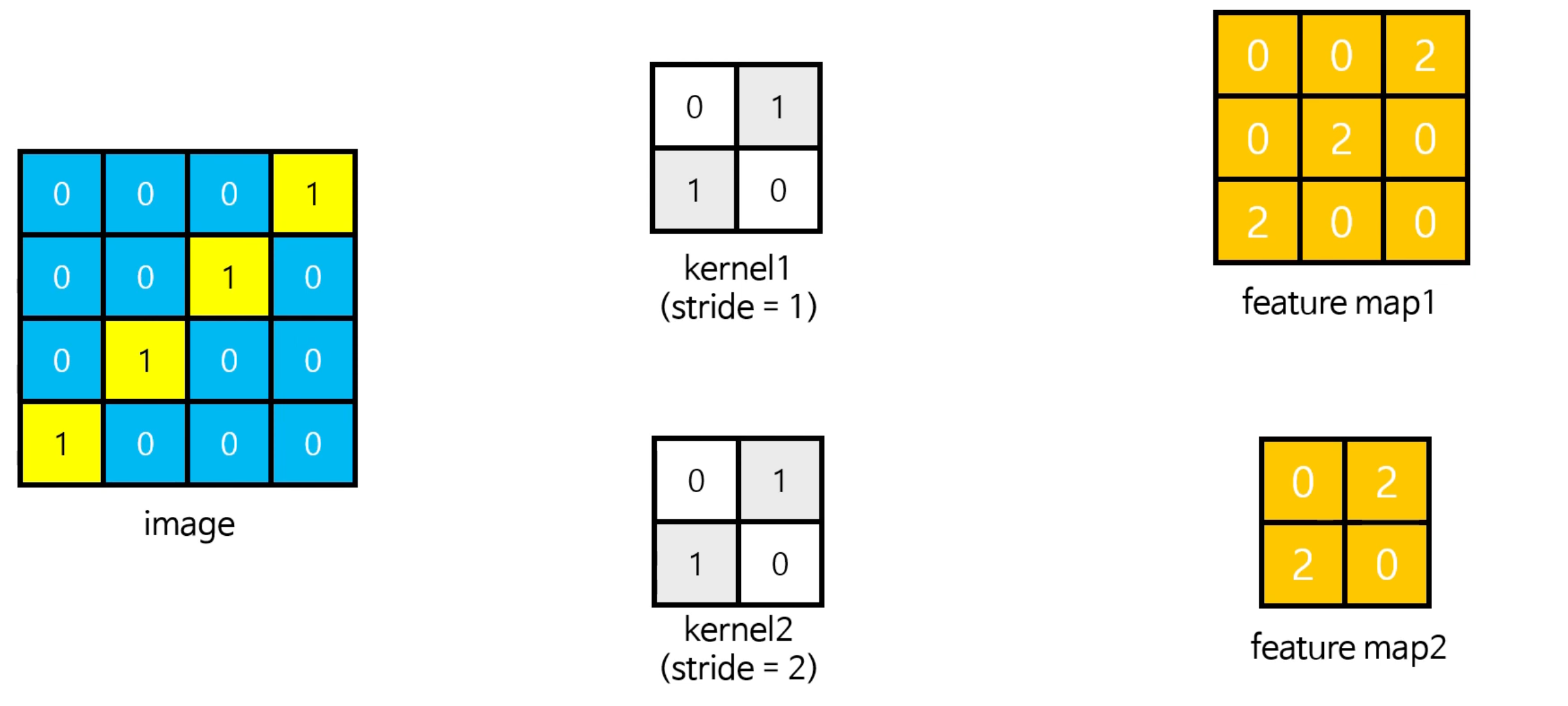
또한 보폭(stride)도 Feature map의 크기와 연산량을 결정짓는 중요한 요소이다. 보폭(stride)가 1일 경우 한칸 씩 움직이며 합성곱연산을 하고 보폭(stride)이 2일 경우 두 칸씩 움직이며 합성곱연산을 한다. 이처럼 kernel의 크기가 같아도 보폭(stride)에 따라 Feature map의 크기가 달라질 수 있다. 마찬가지로 Kernel의 크기와 보폭은 연산량과 모델의 정확성 사이에서 밸런스를 맞추어 설정하면 된다.
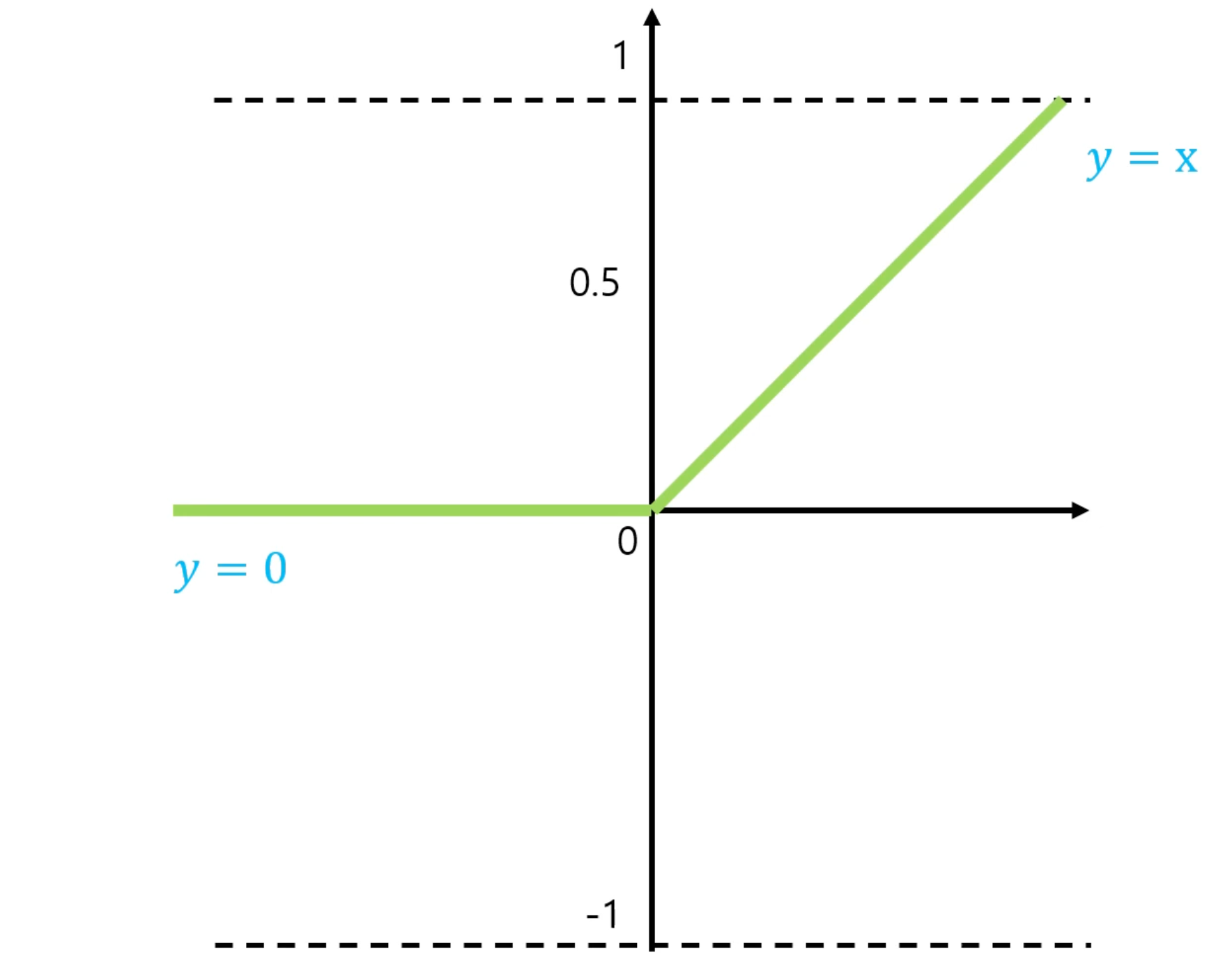
또한 합성곱 층은 보통 활성화 함수(activation function)를 사용하여 비선형성을 도입한다. 대표적인 활성화 함수는 ReLU 함수가 존재하는데, 활성화 함수는 합성곱 층의 출력에 적용이 되어 비선형성을 추가하고 모델이 복잡한 패턴을 학습할 수 있도록 해준다.
풀링 층(Pooling Layer)
풀링 층(Pooling Layer)은 합성곱 층에서 추출된 Feature map의 크기를 줄이는 역할을 한다. 이전에 언급했던 것과 같이 Feature map이 크면 성능은 좋지만 너무 연산량이 급증하여 학습 자체가 불가능해질 수 있기 떄문에 Feature map의 크기를 줄이는 것이 필요하다. 이 때 풀링 층이 사용이 된다.
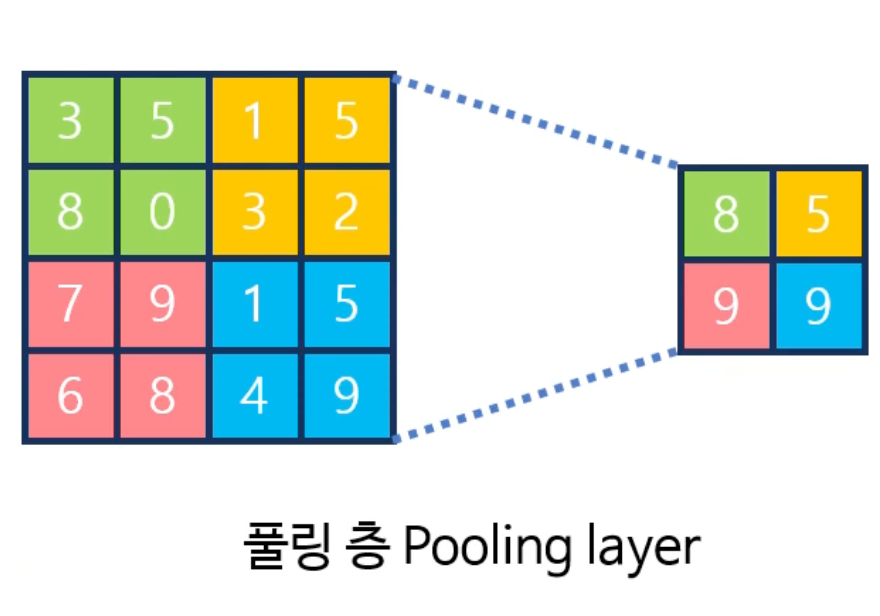
CNN에서 사용하는 풀링 층은 크게 2가지로 구분이 된다.
- 최대 풀링 층(Max Pooling Layer)
- 최대 풀링층은 주어진 풀링 윈도우 내의 값중 최대 값을 리턴한다.
- 평균 풀링 층(Average Pooling Layer)
- 평균 풀링층은 주어진 윈도우 내의 값의 평균을 리턴한다.
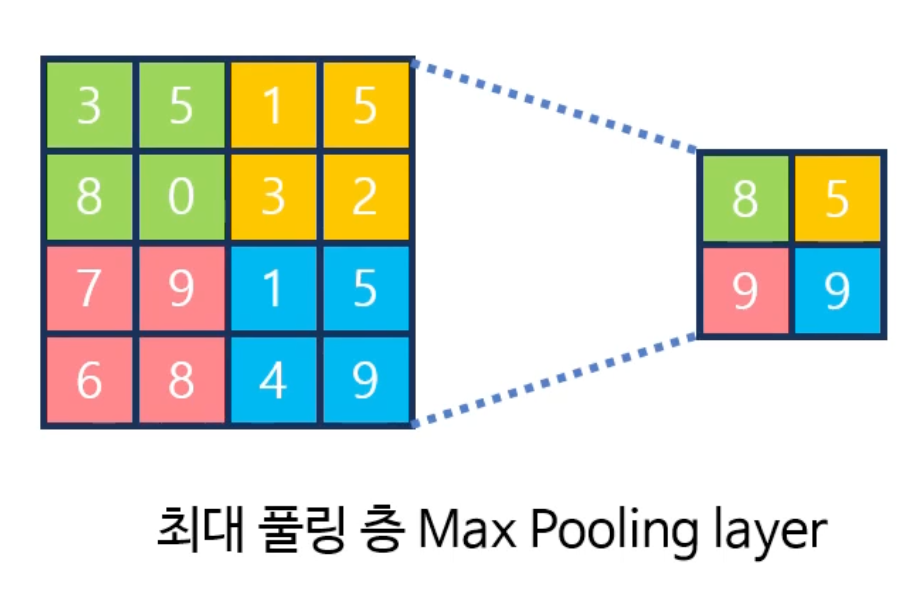
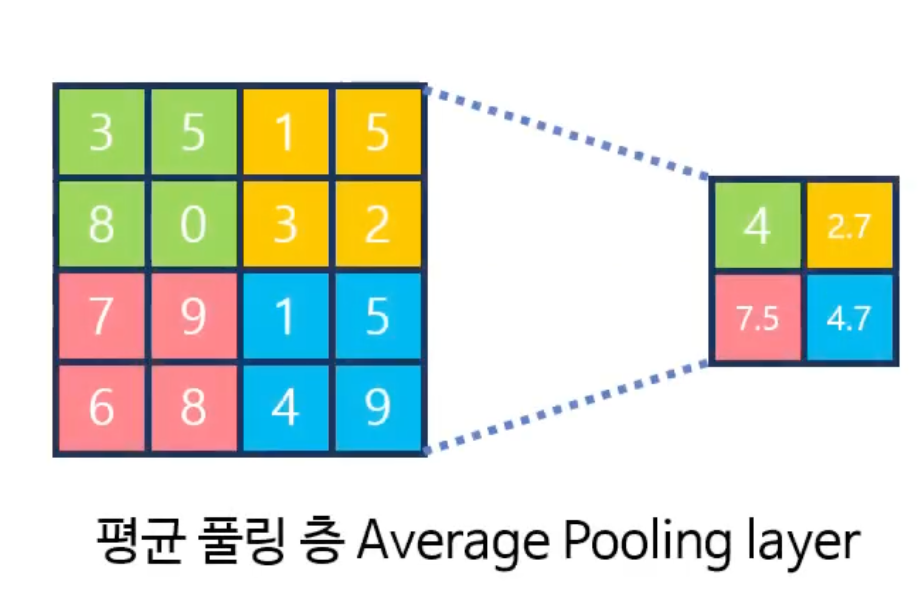
풀링 층을 통해서 공간적인 크기을 줄이고 계산 비용을 줄이면서 중요한 특징을 보존할 수 있다.
밀집층 (Fully-connected Layer, Dense Layer)
밀집층은 추출된 Feature들을 기반으로 최종 출력을 생성하는 역할을 한다.
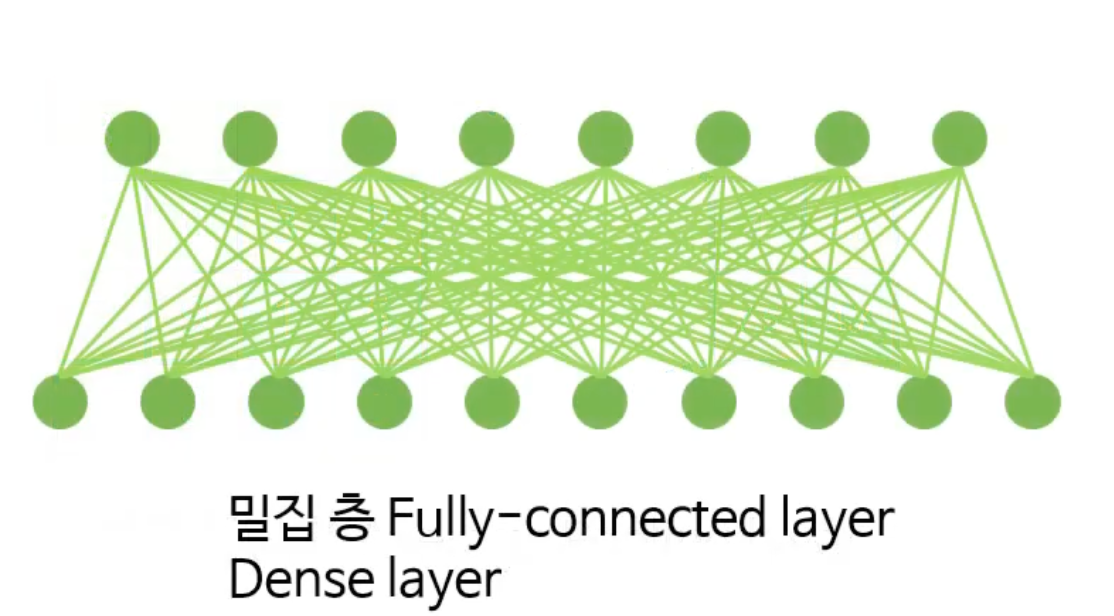
최종 출력을 생성하기 위해 보통 Fully-connected Layer는 CNN 모델의 가장 마지막에 존재한다. Fully-connected Layer 층 직전에는 모든 Local Feature를 1차원으로 만들어주는 Flatten Layer 층을 배치한다. 그런 다음 모든 Local Feature들과 연결된 Fully-connected Layer로 출력값을 보내어 최종 아웃풋을 계산한다. Local Feature들은 '지역적인 확률'이기 때문에 최종확률을 계산하기 위해서는 반드시 전체를 고려해야한다. 그래서 모든 local Feature들의 입력을 받는 Fully-Connected Layer가 마지막 단계에서 필요한 것이다.
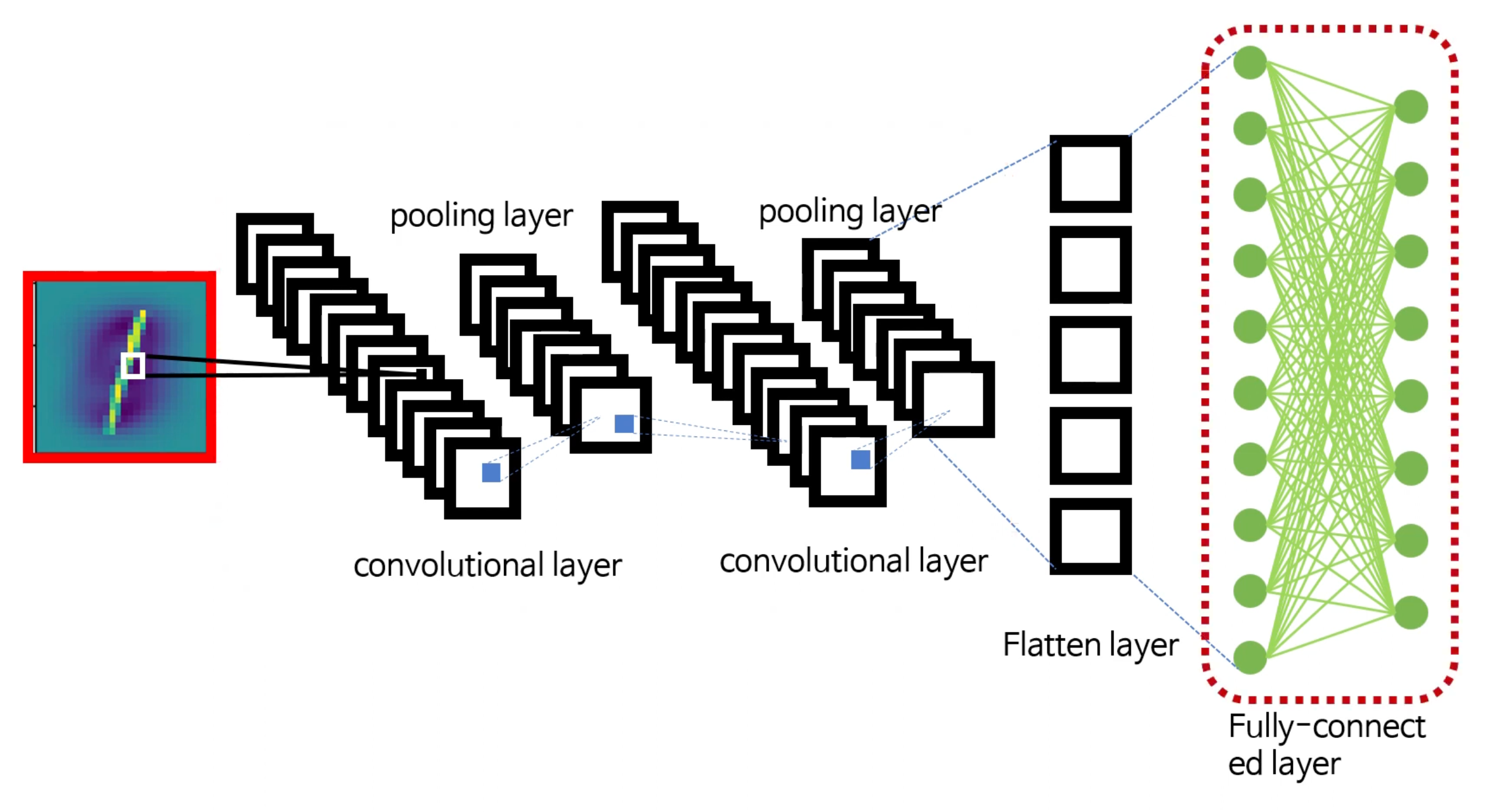
CNN 학습 과정
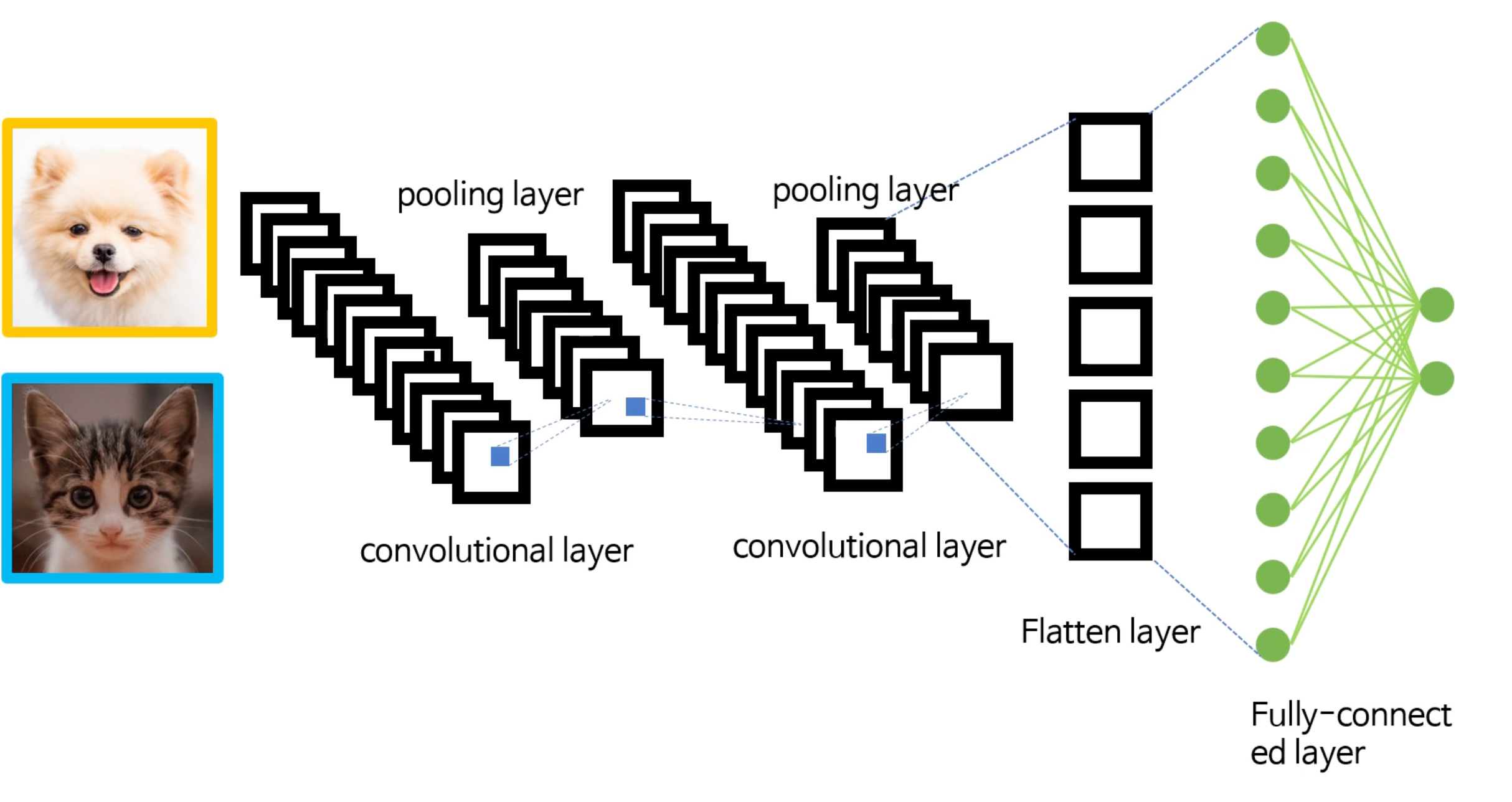
개념적인 이해를 위헤 강아지와 고양이를 구분하는 CNN 모델을 가정해보자. 강아지가 입력값을로 들어올 경우 출력은 1,0이 되고 고양이가 입력값으로 들어올 경우 출력은 0,1이 되어야 한다고 가정한다.
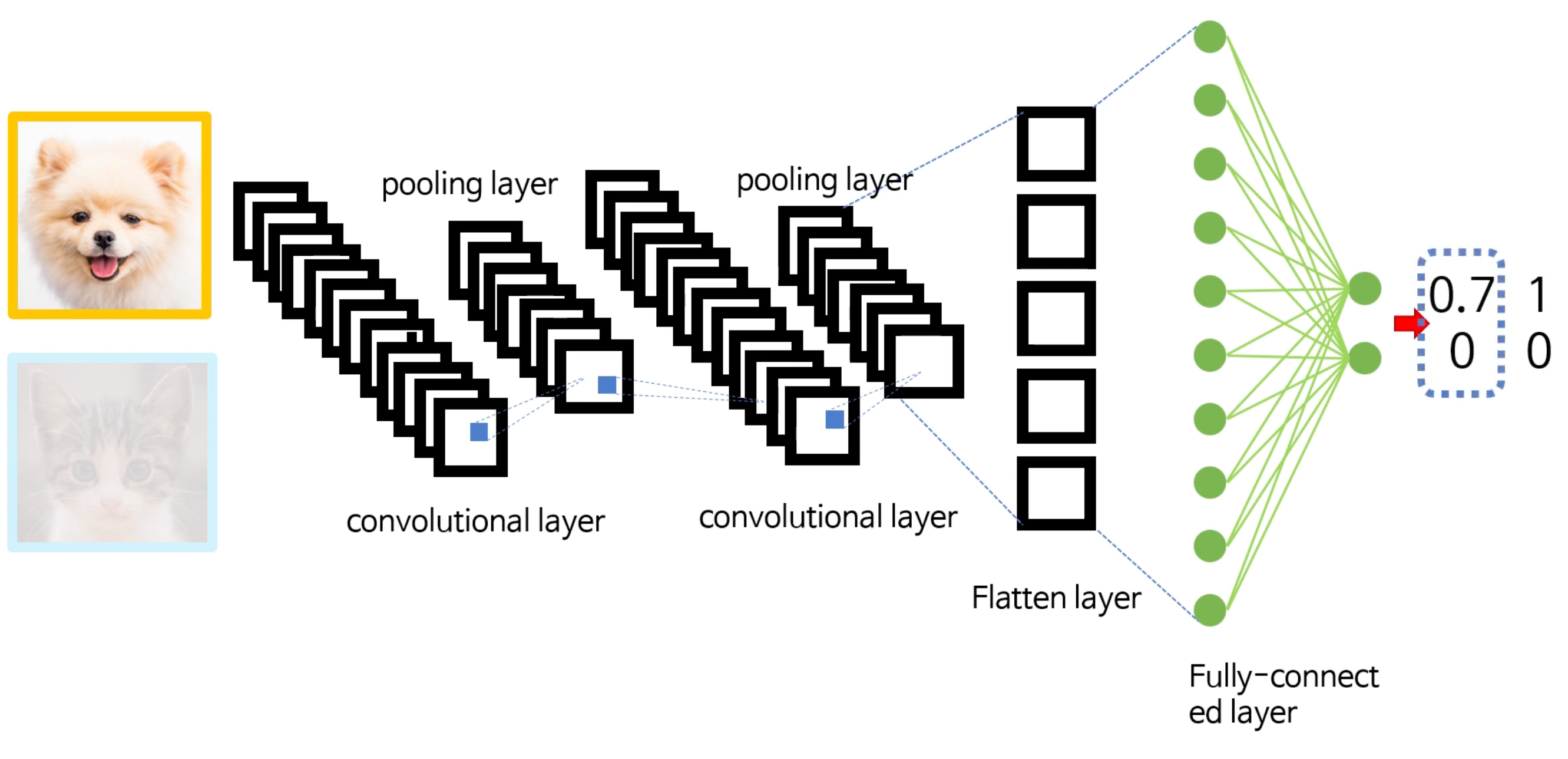
만약 강아지 사진이 들어와서 Feedforward의 결과 최종 출력값이 (0.7, 0)이 나왔다고 해보자. 그러면 오차인 0.3을 줄여나가기 위해 강아지 이미지의 Local Feature들과 유사한 모습이 되어가도록 kernel들의 가중치를 점진적으로 변화시킨다. (고양이의 경우도 마찬가지다!, 물론 kernel 가중치 변화 알고리즘은 역전파와 경사하강법이 사용이 된다!)
이와 같은 과정으로 많은 데이터를 통해 반복학습하게 된다면 각각의 kernel들은 강아지와 고양이의 Local Feature들을 갈 구분하는 kernel들의 가중치로 점차 변화되어 가게 된다.
Code Review
https://github.com/BARAM1NG/Deep_Learning_Hub/tree/main/Deep_Learning
Reference
https://www.youtube.com/watch?v=lDqn1UNwgrY
'Analytics' 카테고리의 다른 글
| [ML/DL] Optuna 사용법 (0) | 2025.01.08 |
|---|---|
| [ML/DL] Precision & Recall Trade-off (1) | 2024.10.19 |
| [RecSys] Matrix Factorization (3) | 2024.10.15 |
| [ML/DL] ResNet (feat: Skip-Connection) (1) | 2024.10.04 |
| [RecSys] 추천시스템 전반적 개요 정리 (3) | 2024.09.29 |