

오늘은 세미나에서 학습했던 AWS의 Lambda에 대해 리뷰하고자 한다.
Server
우선 Lambda 서비스를 이해하기 위해서 Server에 대해 이해해야 할 필요가 있다.
Server란 이름 그대로 서비스를 제공하는 주체로, 여기서 서비스란 사용자가 서버에 접속하여 얻고자 하는 것을 의미한다.
- e.g. 네이버 서버의 경우, https://www.naver.com 를 입력하면 사용자가 원하는 네이버 홈페이지를 보여준다.
→ 사용자는 해당 url을 주소창에 입력하여 네이버 홈페이지를 보길 원하고 네이버 서버는 해당 요청에 홈페이지를 보여주는 것으로 응답한다.
→ 이것이 기초적인 request와 response의 개념이다.
IP
IP주소란 하나의 컴퓨터에 부여되는 고유한 번호다.
- 192.168.2.24 (국가코드 192.168 + 보안네트워크 2 + 네트워크에 연결된 컴퓨터 번호 24)
→ 사람은 출생신고를 하면 주민등록번호라는 고유번호를 부여받는다.
→ 하지만 우리가 주민등록번호를 부르지 않고 이름을 부르듯이, 서버 또한 편하게 부를 수 있는 이름이 있다.
→ 우리는 그걸 url주소(도메인주소)라고 부른다. (url주소 = ip주소의 이름)
Serverless
Server를 받는다는 것은 컴퓨터 한 대를 임대받는 것과 같다고 생각하면된다. 그러나 서버를 임대받게 되면 다양한 프로비저닝을 직접하고 조절해야 해야하는데, 그것을 모두 전문 개발인력이 아닌 일반인이 하기에는 꽤 많은 자원이 소요된다. 때문에 이를 극복하기 위해 Serverless 서비스를 사용한다.
Serverless란 서버 공급자(ex. AWS)가 프로비저닝을 하고 요청이나 특정 이벤트가 있을 때, 어플리케이션을 실행시키는 것이다. 특히 사용자 입장에서는 서버의 몇 가지 기능만을 필요로 하는 경우에 가장 최적의 선택이다. Serverless의 대표적인 예시가 오늘 살펴볼 AWS의 Lambda 서비스이다.
AWS Lambda

함수 생성하기
람다는 함수 기능을 제공한다. 이 말은 즉, 우리가 만들 함수를 24시간 켜져있는 서버에서 돌릴 수 있다는 것을 의미한다.
해당 기능을 사용하기 위해 함수 -> '함수 생성' 버튼을 클릭한다.
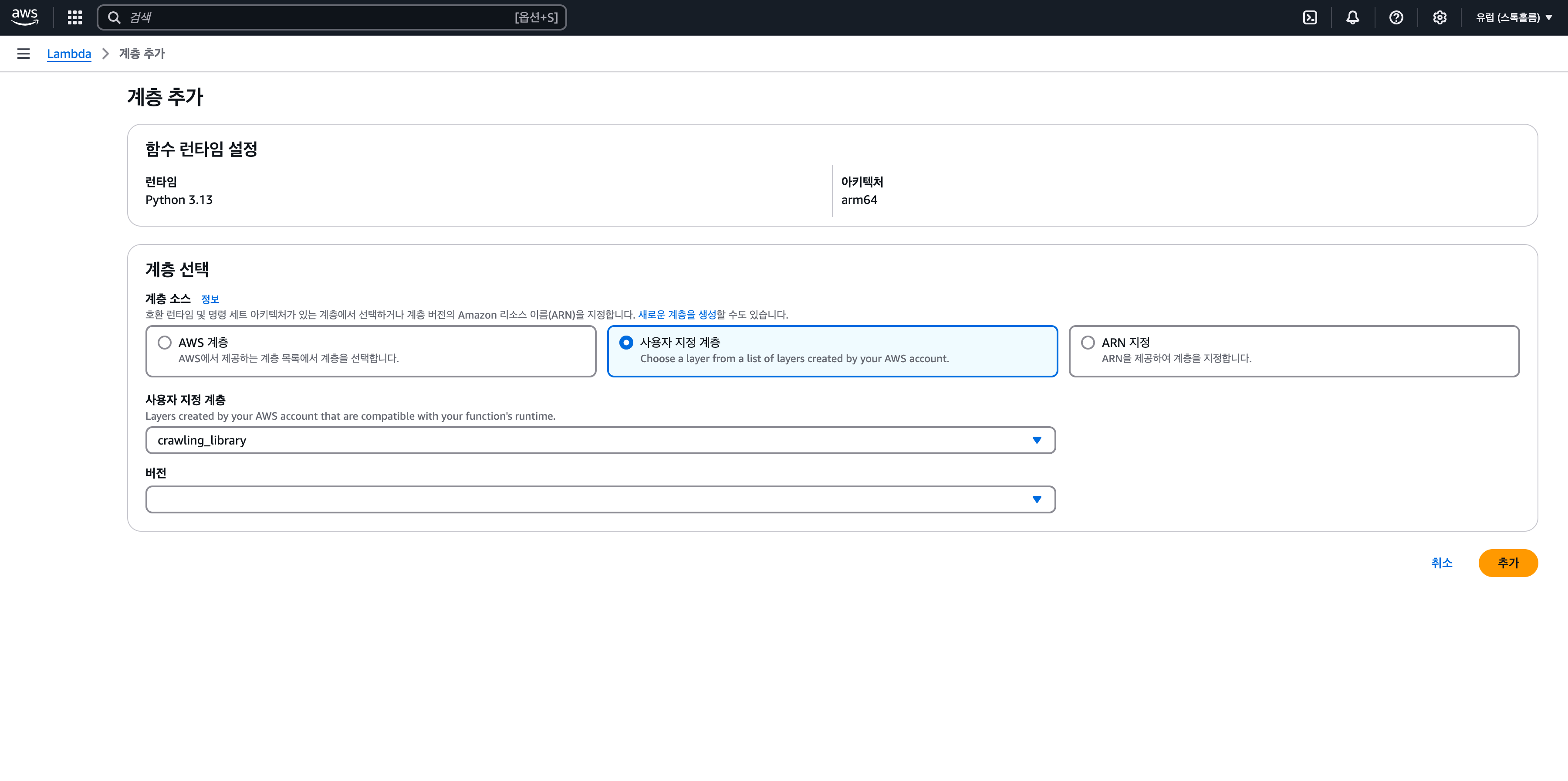
2. Layer 붙이기
Lambda는 pandas, numpy 등의 라이브러리를 지원하지 않기 때문에, 우리가 직접 Layer에 연결해야 한다.
- 생성한 Lambda 함수의 '함수 개요' 내 'Layers' 클릭 -> 계층의 [Add a layer] 버튼 클릭 -> '새로운 계층을 생성' 클릭
- 이름에 레이어 이름 작성 및 설명에 어떤 레이어인지 작성.
- '업로드' 버튼 클릭 -> 본인이 만들 함수에 사용할 Library 파일을 .zip파일로 업로드
- 호환 런타임에는 본인이 사용할 프로그래밍 언어의 버전을 선택한 후, 생성.
- 다시 생성한 Lambda 함수 페이지로 돌아가서 '함수 개요' 내 'Layer' 클릭 후, [Add a layer] 버튼 클릭
- 계층 소스에서 '사용자 지정 계층' 선택
3. 함수 설정
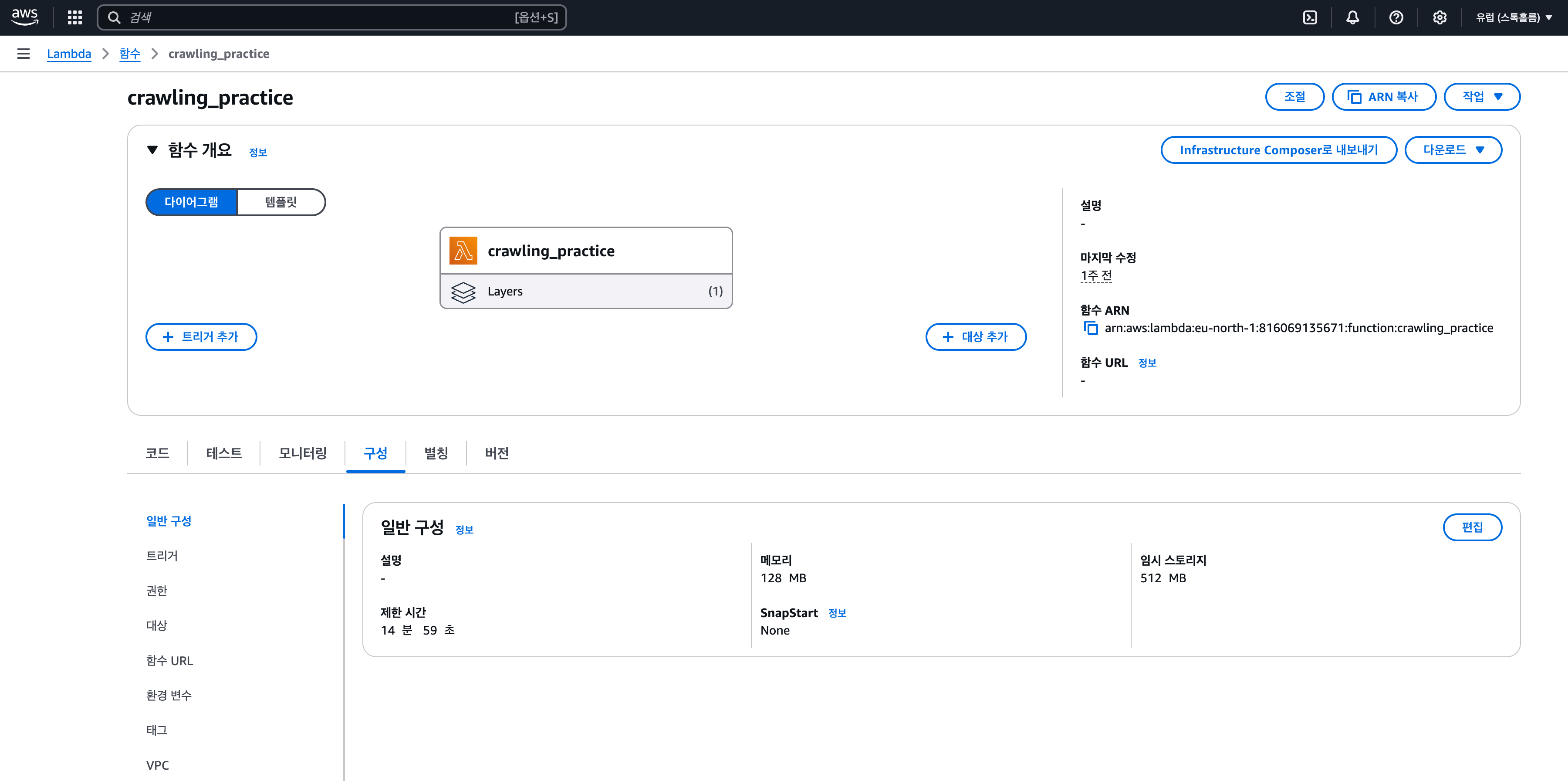
Layer를 편집한 후에는 본인이 만든 함수의 코드 입력 및 제한 시간을 설정한다.
- 생성한 Lambda 함수 페이지 구성에서 일반 구성을 선택한 후, 편집 버튼을 눌러 제한 시간을 변경
- 제한 시간은 람다에서 지정한 함수를 실행할 수 있는 최대 시간을 의미한다.
- 생성한 Lambda 함수 페이지의 '코드'의 lambda_function에 원하는 기능의 함수 넣기
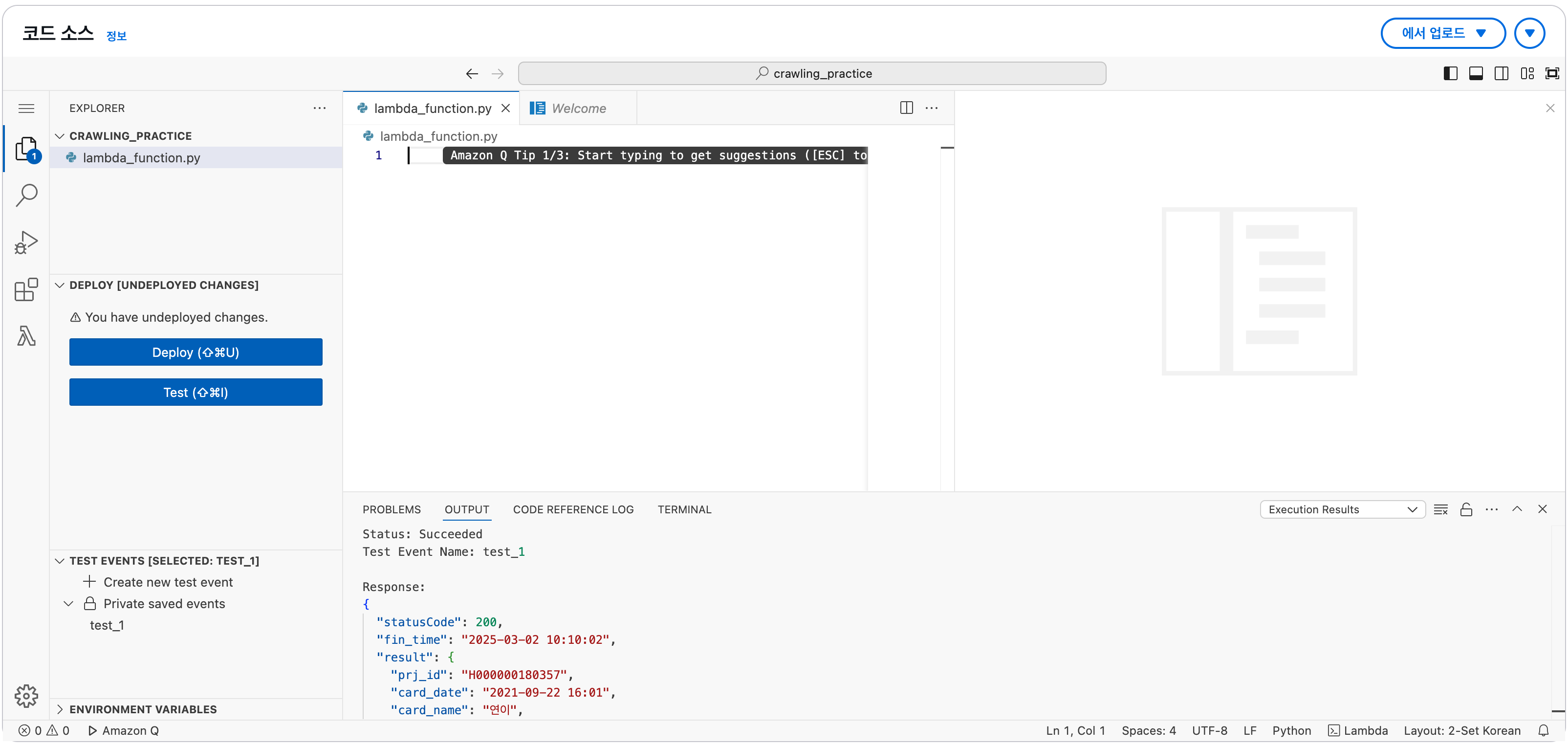
Test 하기
그 다음 생성한 함수의 기능을 Test한다.
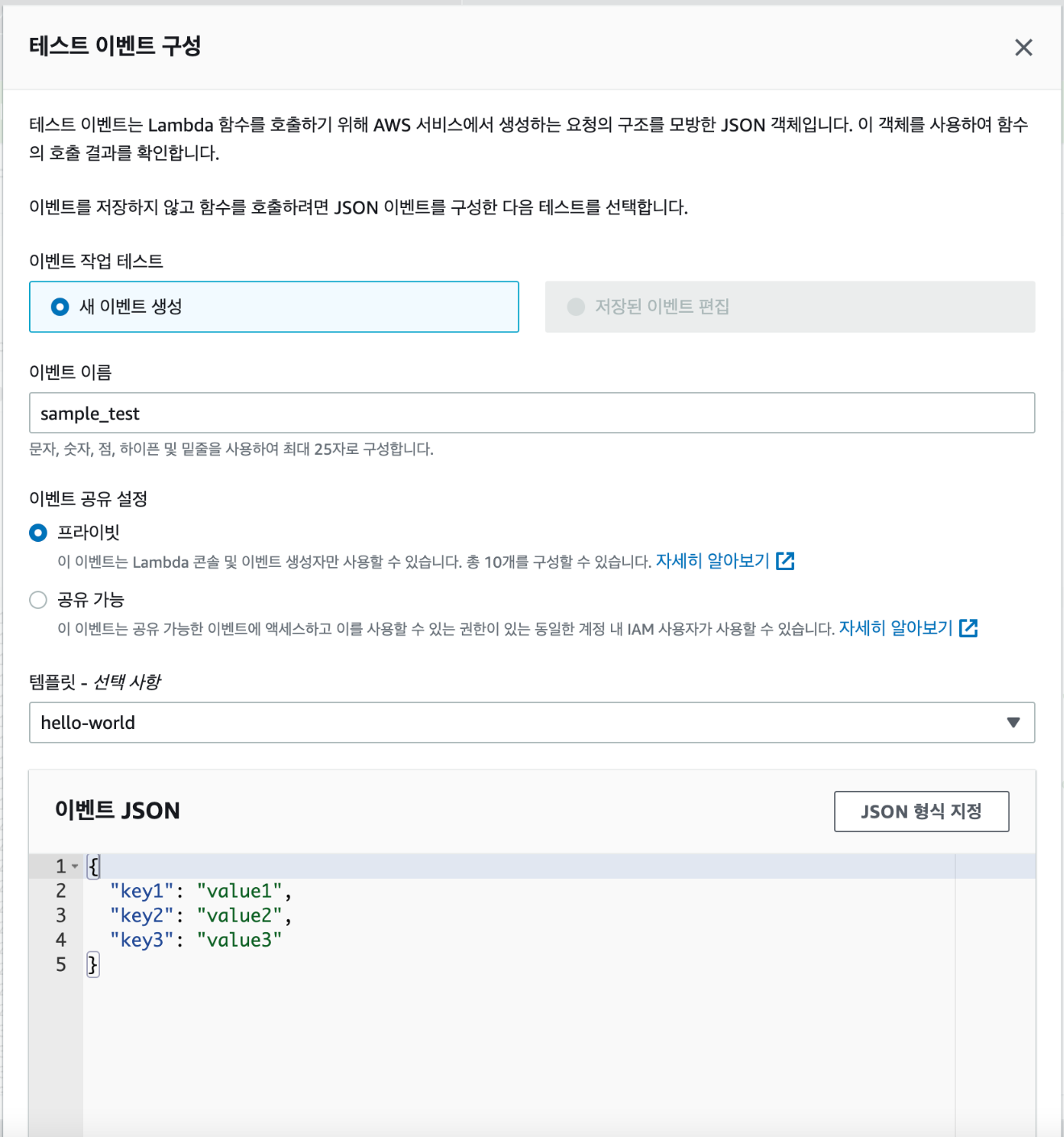
- 위 함수의 코드 부분에서 Test 버튼을 클릭한다.
- Test 버튼을 클릭하면, 테스트 이벤트 구성이라는 팝업창이 뜨는데, 이 때 이벤트 이름은 임의로 설정한 후 저장한다.
- 그 후, 코드 부분의 Deploy 버튼을 클릭한다.
- 마지막으로 Test 버튼을 다시 클릭한다.
- statusCode에 200이 뜨면 Test가 성공한 것이다.
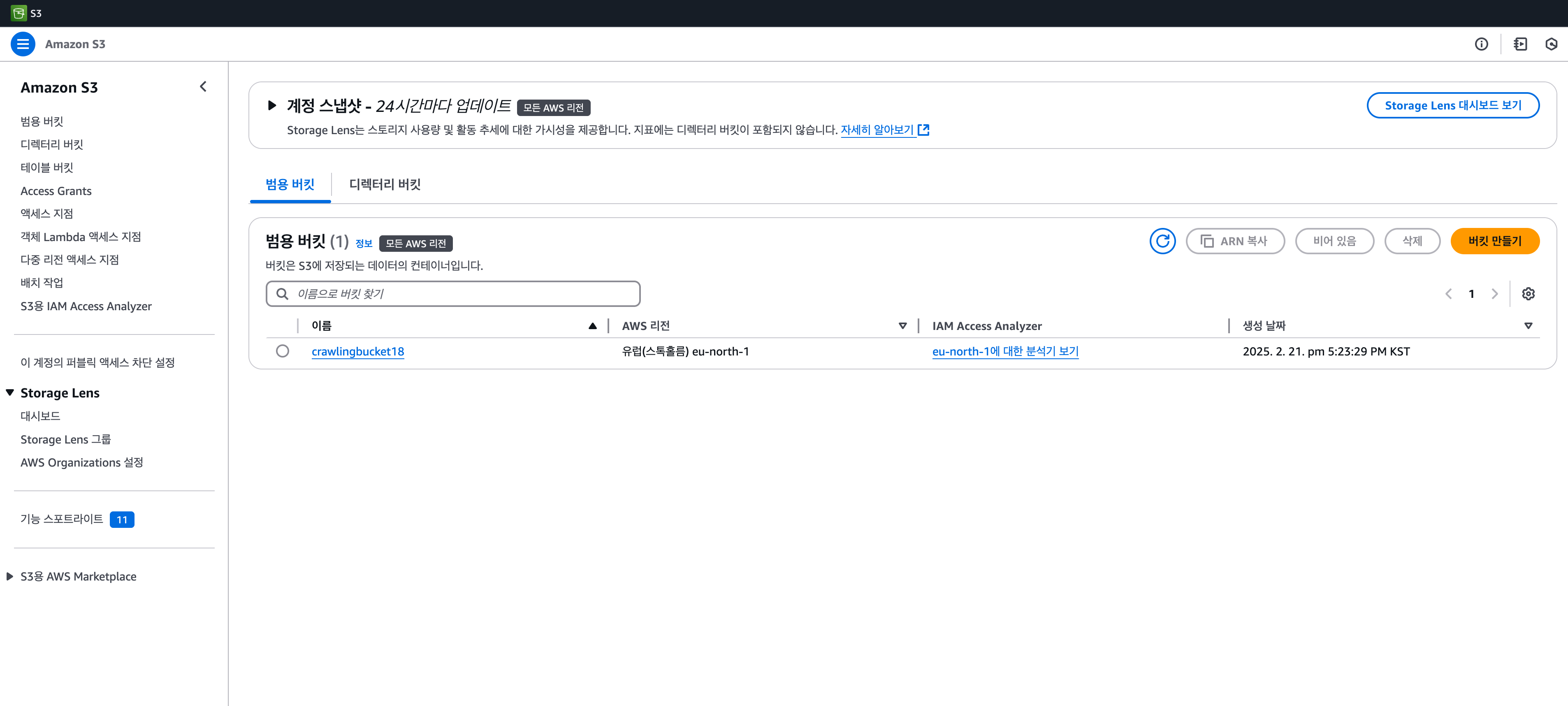
S3 Bucket 생성
만약 크롤링하는 코드를 Lambda를 이용하여 스케줄링하는 경우, 크롤링된 데이터가 저장될 저장소가 필요하다. 이 때 사용되는 것이 S3 Bucket이다.
- AWS에 S3을 검색한 후, 버킷 만들기 버튼을 클릭한다.
- 적절한 Bucket 이름을 만든 후에 Lambda 함수와 같은 Region을 선택한다.
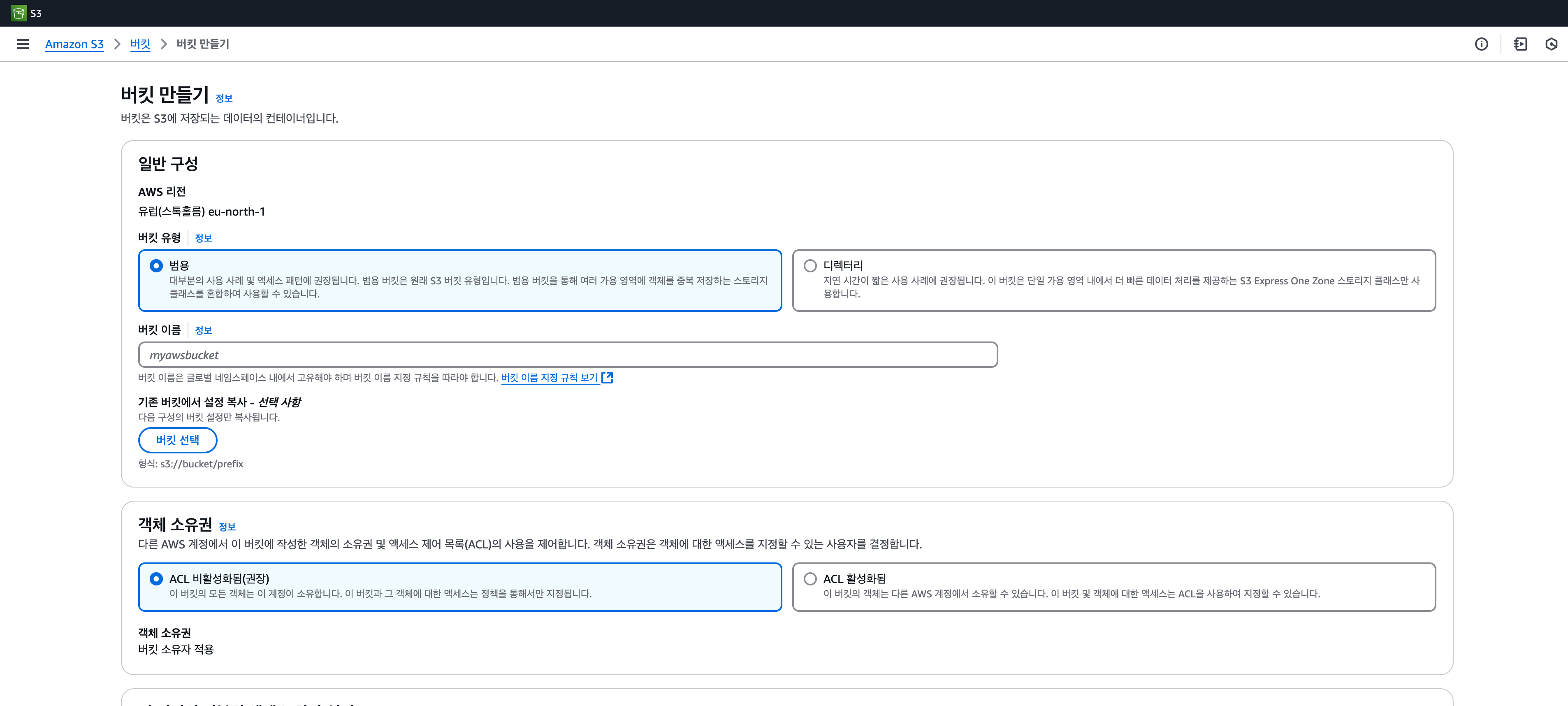
- 모든 퍼블릭 엑세스 차단 체크를 해제한다.
- 이 때, '현재 설정으로 인해 이 버킷과 그 안에 포함된 객체가 퍼블릭 상태가 될 수 있음을 알고 있습니다.'는 체크.

- 버킷 만들기를 클릭한다.
그 후 S3에 권한을 부여하는 작업이 필요하다.
- 생성한 S3 Bucket을 클릭한 후, 권한을 선택한다.
- '버킷 정책' 부분에서 '편집' 버튼을 클릭한다.
- 아래 코드를 본인에게 맞게 수정하고 코드를 붙여넣는다. (필요없는 것은 삭제해도 무방)
{
"Version": "2012-10-17", // Bucket Policy의 문법이 언제 날짜 기준으로 확정된 문법을 사용하는지 → 2008-10-17 버전 후 2012-10-17 버전이 있는데, 그 뒤로는 업데이트가 안됐음
"Id": "S3PolicyId1", // Bucket Policy의 고유 아이디, 자동으로 부여되는 경우가 많음
"Statement": [
{
"Sid": "IPAllow", // 각 Statement의 고유 아이디. 무슨 역할을 하는 policy인가
"Effect": "Allow", // 버킷에 대한 명령을 허락(allow)하거나 거부(deny). 특정 사용자에 대해 명령을 제한하거나, 허용하는 식으로 사용
"Principal": {"AWS": "arn:aws:iam::spark323:user/spark"}, // Bucket Policy의 적용대상 (spark323 아이디의 유저에 대해서)
"Action": [ // Bucket Policy에서 허용한 Action
"s3:GetObject", // 객체 가져오는 행동
"s3:GetBucketLocation", // 버켓 위치를 확인하는 행동
"s3:ListBucket", // 버켓 리스트를 확인하는 행동
],
"Resource": "arn:aws:s3:::bucketname/*", // 대상이 대는 Bucket에 대한 명세
"Condition": { // 어떤 조건 하에
"NotIpAddress": { // 이 IP비허용
"aws:SourceIp": "1.1.1.1/32"
},
"IpAddress": { // 이 IP허용
"aws:SourceIp": [
"192.168.1.1",
"192.168.1.2/32",
]
}
}
}
]
}- 위의 JSON 권한 형식을 해석하자면,
- 계정 spark323 아이디인 유저에 대해서
- Resource(해당버킷)에 대해
- Action(객체를 가져오거나 버켓 위치를 확인하거나)을 Effect(허용) Condition(아이피 192.168.1.1, 192.168.1.2/32 인 하에) 한다는 의미.
- 변경 사항 저장 후, 크롤링 한 결과를 생성한 버킷에 넣기
- 크롤링 한 결과를 버킷에 넣기 위해서는 Lambda의 함수의 코드 부분에 아래와 같이 S3에 저장하는 코드를 추가로 입력한다.
# s3에 저장하는 코드
#주로 json으로 저장함 (왜냐하면 데이터프레임으로 저장하면 용량이 커졌을 경우에 데이터가 손실될 위험이 있기 때문)
import boto3
s3_client = boto3.client('s3')
bucket = '크롤링 할 버킷 이름'
s3_client.upload_file(donor_file_path, bucket, f'{donor_file_name}.json')
- Deploy 후, Test 해보기
- 버킷에도 json 파일이 생성되면 성공.
스케쥴링
마지막으로, 해당 함수를 특정 시간마다 실행할 수 있도록 스케쥴링 해주는 작업이 필요할 수 있다.
- 람다 함수의 '트리거 추가' 클릭
- 트리거 구성에서 'EventBridge'를 선택한 후, 규칙을 생성한다.
- 규칙 설명에는 원하는 시간을 입력하고 아래 예약 표현식에 rate(원하는 시간)으로 입력한 후, 추가 버튼을 클릭한다.
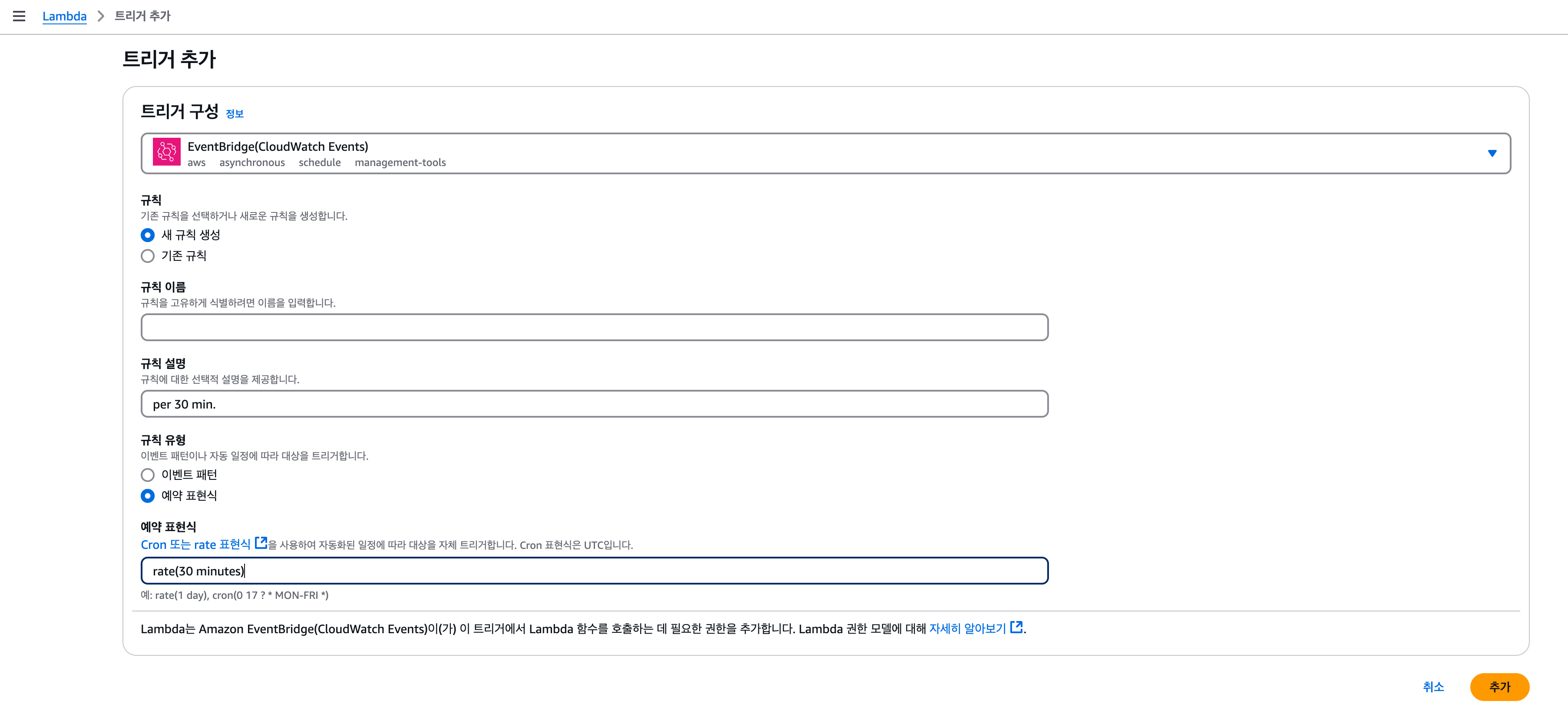
- 그 후, S3에 해당 시간마다 잘 저장되는지 확인하고 마무리한다.
Reference
[AWS] 📚 S3 개념 & 버킷 · 권한 설정 방법
S3 (Simple Storage Service) 개념 AWS S3는 업계 최고의 확장성과 데이터 가용성 및 보안과 성능을 제공하는 온라인 오브젝트(객체) 스토리지 서비스이다. (참고로 S 앞글자가 3개라서 S3 이라고 한다.) 쉽
inpa.tistory.com
'ETC' 카테고리의 다른 글
| ML 프로젝트 폴더 구조 (0) | 2024.04.11 |
|---|