

컴퓨터는 텍스트를 이해하지 못한다. 때문에, 컴퓨터가 텍스트를 이해할 수 있도록 잘 표현해주어야 하는데, 우리는 그것을 Text Representation이라고 한다. 즉, 우리는 NLP에 있어서 항상 텍스트를 어떻게 컴퓨터가 이해할 수 있도록 변환할까를 계속 고민해야한다.
오늘은 컴퓨터가 텍스트를 이해할 수 있도록 변형하는 몇가지 기법을 소개해보고자 한다.
원-핫 인코딩(One-Hot Encoding)
원-핫 인코딩(One-Hot Encoding)은 문장내에 등장한 모든 단어의 차원을 나열한 것을 의미한다. 아래의 예시와 같이 문장이 있는 경우, 문장에 들어가는 단어의 수만큼 차원을 만들고 각 차원마다 단어의 위치를 지정하여 해당 단어가 나오는 차원에 1을 부여하는 것이다.

Bag Of Words
원-핫 인코딩을 변형한 것이 바로 Bag of words방식이다. 이 방식은 단어의 등장 빈도로 텍스트를 벡터화 시킨 것을 의미한다. 즉, 원-핫 인코딩한 것을 모두 합쳤다고 생각하면 된다. 아래 예시는 Bag of words의 방식의 예시인데, 이를 보면 문장에서 해당 단어의 등장 횟수마다 +1이 되어 있는 것을 확인할 수 있다.

그러나, 원-핫 인코딩 방법이나 Bag Of Words 방식의 경우, 문장의 길이가 길어지는 경우에 벡터 차원이 너무 높아져 계산량이 너무 증가하는 단점과 단어 간의 유사성을 반영하지 못한다는 단점이 존재한다. 때문에, 아래와 같이 Word-Embedding이라는 개념을 도입하여 문제를 해결한다.
Word Embedding
Word Embedding이란, 단어를 특정 길이의 벡터로 표현하는 것을 의미한다. 말로만 보면 이해되지 않을 것 같기에 아래 예시를 함께 보자.
아래 예시를 보면 cat, kitten, dog와 같은 단어들이 1차원 벡터로 표현되어 있는 것을 확인할 수 있다. 그런데, 여기서 하나 의구심이 들 수 있을 것 같다. 각 벡터의 원소는 무슨 기준으로 Embedding된 것일까?
사실 임베딩 된 숫자는 어떠한 기준으로 표현이 된 것인지 정확히 알지 못한다. 다만, 각 벡터들이 잘 표현되고 독립적으로 나타날 수 있도록 표현한 것이라고 할 수 있겠다.

Word2Vec
Text Representation에서 또 중요한 점은 바로 단어들 간의 상관관계를 표현할 수 있는 숫자로 Embedding하는 것이다. 즉, 유사한 단어들 간의 관계성을 가진 Word Embedding이 필요한 것이다. 이 때 대표적으로 사용되는 알고리즘이 Word2Vec 알고리즘이다.
Word2Vec은 대표적으로 CBOW와 Skip-Gram 2가지 알고리즘을 사용하여 학습된다.
- CBOW
CBOW는 수능 영어 빈칸 추론 문제와 같이 전후 문맥을 고려하여 중간단어를 학습하는 것을 의미한다. 예를 들어, I __ pizza. 와 같은 단어가 주어질 때, I와 pizza를 이용해 그 중간단어를 추론하는 방법이다. 즉, 주변 문맥 단어가 주어졌을 때, 중간 단어의 확률이 최대가 되도록 네트워크를 학습시켜간다.
- Skip-Gram
Sip-Gram의 경우 CBOW와 반대되는 개념으로 중간 단어가 주어질 때, 그 주변 단어를 고려하여 학습하는 과정이다.
예를 들어 아래와 같은 상황이 있다고 가정하자. 중간 단어 into가 들어갔을 때, 앞 뒤로 어떤 단어가 들어갈지를 예측하게 된다. 즉 중간을 기준으로 주변 단어(주변 단어의 개수 지정 가능)를 고려하여 학습을 진행하게 되는데, 그런 식으로 규칙을 학습하여 중심 단어가 주어졌을 때, 주변 문맥 단어의 확률이 최대가 되도록 네트워크를 학습시켜 간다.

Word2Vec에서 단어들을 유추하는 과정을 계산식으로 표현하면 아래와 같다.
예를 들어, man:woman::king:d 의 관계식이 존재한다고 생각해보자. 우리는 d를 유추해야하는 상황에 놓여있다. d는 아래와 같은 수식으로 유추할 수 있다.

그리고 아래와 같이 번호를 매길 때 그래프 상으로 다음을 추론할 수 있다.

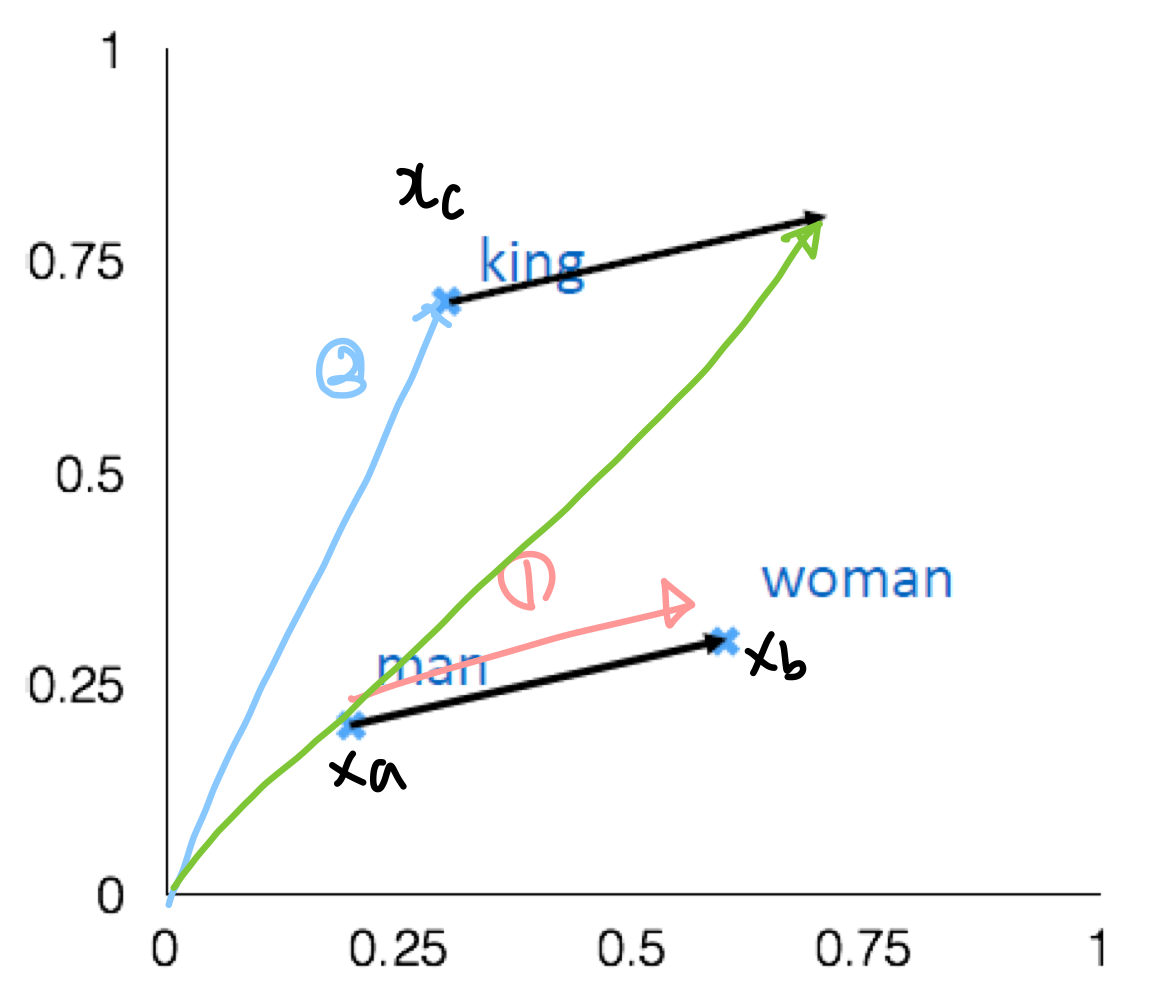
초록색 화살표가 최종적으로 유추한 d값이 되는 것이고 아마도 그 값은 관계성을 고려할 때, Queen이 됨을 유추해볼 수 있다.
Reference
경희대학교 산업경영공학과 머신러닝 수업
'Analytics' 카테고리의 다른 글
| [Causal Inference] Causal Inference for The Brave and True 리뷰 (0) | 2024.08.12 |
|---|---|
| [ML/DL] Recurrent Neural Network(RNN) (0) | 2024.08.09 |
| [ML/DL] 인공 신경망(Neural Networks) (0) | 2024.05.10 |
| [Data] 텐서(Tensor) 구조와 연산 (0) | 2024.05.08 |
| [ML/DL] Activation function(활성화 함수)의 쓸모 (0) | 2024.05.05 |