

지금까지 트랜스포머 모델에 대해 공부하며 어려움이 많았다. 원문도 읽어보고 다양한 동영상을 접해봤지만 완벽하게 정리되는 느낌은 아니였다.
그런데, 얼마 전 신박AI에 대한 영상을 접하게 되었고 단연코 지금까지 본 트랜스포머 영상 중 가장 헷갈렸던 부분들을 긁어주는 영상이었기에 다시 한번 정리해보고자 한다. 신박AI와 같은 양질의 컨텐츠를 나도 나중에 제작하겠으리라 다짐하며 글을 시작한다.
Intro
트랜스포머는 인공지능 역사에 길이 남을 이정표로, 모든 사람이 주장하는 딥러닝계의 게임 체인저 모델이다.
2017년에 등장한 이후, 여러 트랜스포머 기반 모델들이 발표되었다. 아래 사진과 같이 트랜스포머는 자연어 처리 뿐 아니라 시각, 청각, 다중 모드, 강화 학습 등 딥러닝의 다양한 영역에 중요한 영향을 미치고 있다.

트랜스포머 구조는 아래와 같이 생겼다.

트랜스포머는 크게 인코더(Encoder)와 디코더(Decoder) 부분으로 나누어져 있다. 그리고 트랜스포머의 모델을 자세히 살펴보면 같은 블록(Layer)가 반복해서 나오는 것을 볼 수 있다. 이처럼 트랜스포머의 구조는 복잡해보여도 그 안에있는 컴포넌트들은 계속 반복해서 나오는 구조이기에 영상을 보면 쉽게 이해할 수 있을 것이다. (영상을 보면 훨씬 쉽게 이해가 된다!)
이제 예시를 사용하여 트랜스포머 학습 메커니즘에 대해 알아보자.
트랜스포머 모델을 학습시키기 위한 첫번째 단계는 데이터셋을 만드는 일이다.
모든 데이터셋에서 모든 단어들을 추출해서 단어장을 만들고

각 단어(토큰)에 인덱스를 배정하여 모델이 처리할 수 있는 데이터로 변환을 해준다.

예를 들어 만약 아래와 같은 입력(How are you?)과 출력(<SOS> I am) 을 학습을 시키게 되면

아래와 같이 변환이 되어 트랜스포머 모델에 들어가게 된다.

실제 <Attention Is All You Need> 논문에서는 영어-독일어 번역 학습을 위해 3만 7천개의 토큰을 사용했다고 한다.
Encoder(인코더)
먼저 트랜스포머의 인코더 부분을 살펴보자.

입력 임베딩 + 위치 인코딩
맨처음 트랜스포머에 입력문장이 들어갈 때, 가장 먼저 해야할 것은 단어 임베딩이다. 입력 임베딩 단계에서는 입력 단어들 [5, 8, 9]가 들어갈 때, 각각의 단어들의 임베딩 벡터들을 출력한다. 우리가 다루고 있는 예시의 임베딩 레이어에서는 11개의 단어들을 압축하여 길이가 6인 밀집벡터로 바꿔주는 레이어라고 생각하면 된다. (실제 트랜스포머 논문에서는 3만 7천개 단어를 512차원의 단어 임베딩으로 압축했다고 한다.) 이렇게 단어를 밀집벡터로 압축함으로써 많은 단어 정보를 효율적으로 처리할 수 있게 된다.

입력 임베딩을 한 후, 위치 인코딩(Position Encoding)이 진행된다. 트랜스포머 내에서는 문장 내의 단어의 위치를 인코딩하고 있다. 언어(특히 영어)의 경우는 어순이 문장의 의미에 아주 중요한 역할을 한다.
아래와 같이 어순이 달라지게 되면, 문장의 의미가 완전히 반대가 되어버리게 된다.

그러므로 같은 단어일지라도 고유한 위치정보를 입력하게 된다면 개가 물었는지, 물렸는지에 대한 정보를 보다 더 정확하게 전달할 수 있게되어 트랜스포머가 문장 전체의 의미를 더 잘 처리하게 된다.

트랜스포머는 아래와 같은 공식으로 단어의 위치를 인코딩한다.

위 공식의 의미를 하나하나 살펴보자.

- $d_{model}$: 단어 임베딩의 길이 (예제에서는 6)
- pos에는 0, 1, 2가 차례대로 들어간다.
- 짝수 번째(0, 2, 4) 단어에 해당하는 i는 왼쪽($sin$) 공식에 대입
- 홀수 번째(1, 3, 5) 단어에 해당하는 i는 오른쪽($cos$) 공식에 대입
위의 순서를 따라 계산하게 되면 아래와 같이 위치 인코딩 값을 계산할 수 있게 된다.

이렇게 계산된 위치 임베딩(왼쪽)과 입력 임베딩(오른쪽)을 서로 합해주기만 한다면 입력+위치 임베딩 벡터를 구할 수 있게된다.

⭐️ 다중헤드 어텐션
위에서 만들어진 입력+위치 임베딩 벡터를 트랜스포머의 다중헤드 어텐션에 넣을 차례이다.
(트랜스포머의 다중헤드 어텐션 != seq2seq 어텐션)
트랜스포머의 어텐션은 seq2seq과 다르게 입력 문장 안에서 단어간의 관계성을 파악한다. 입력 시퀀스 내에서 자체 단어들 간의 관계성을 주목한다하여 트랜스포머의 어텐션 메커니즘을 self-attention이라고 한다.

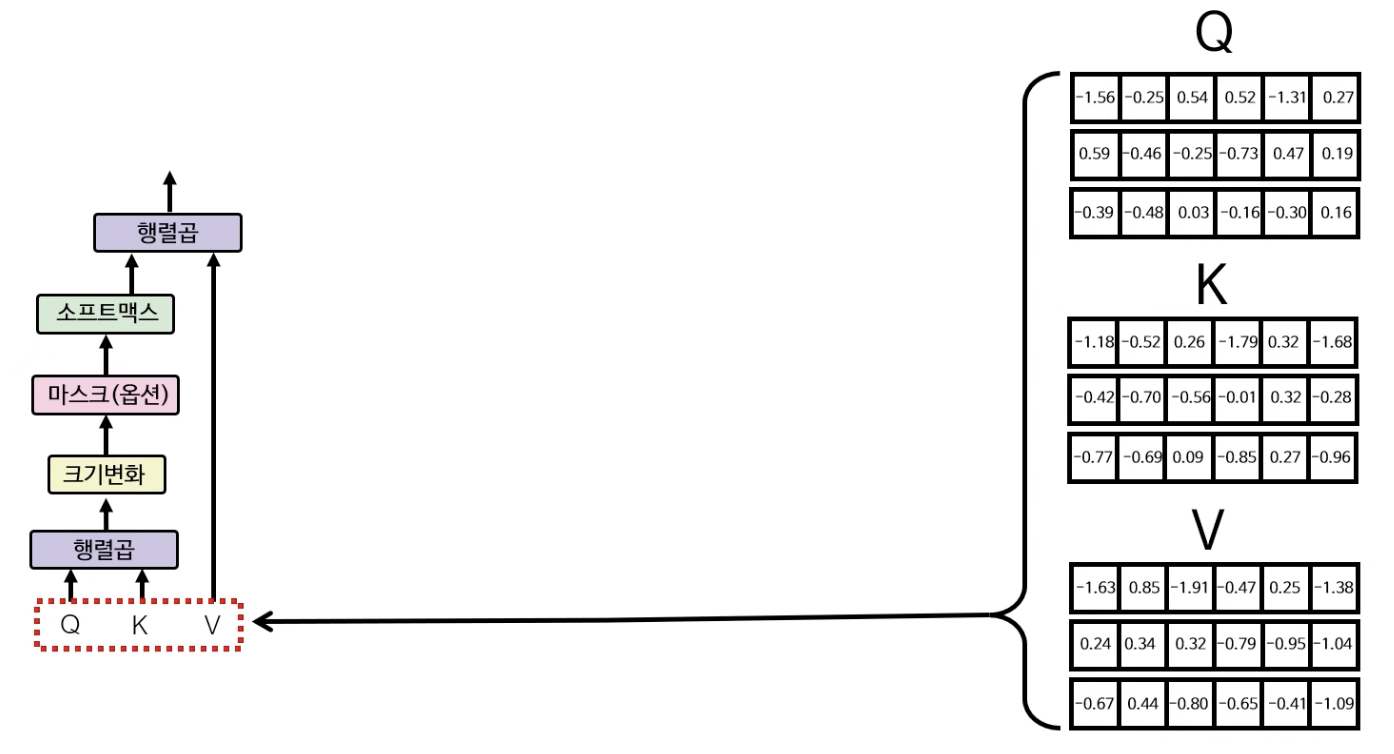
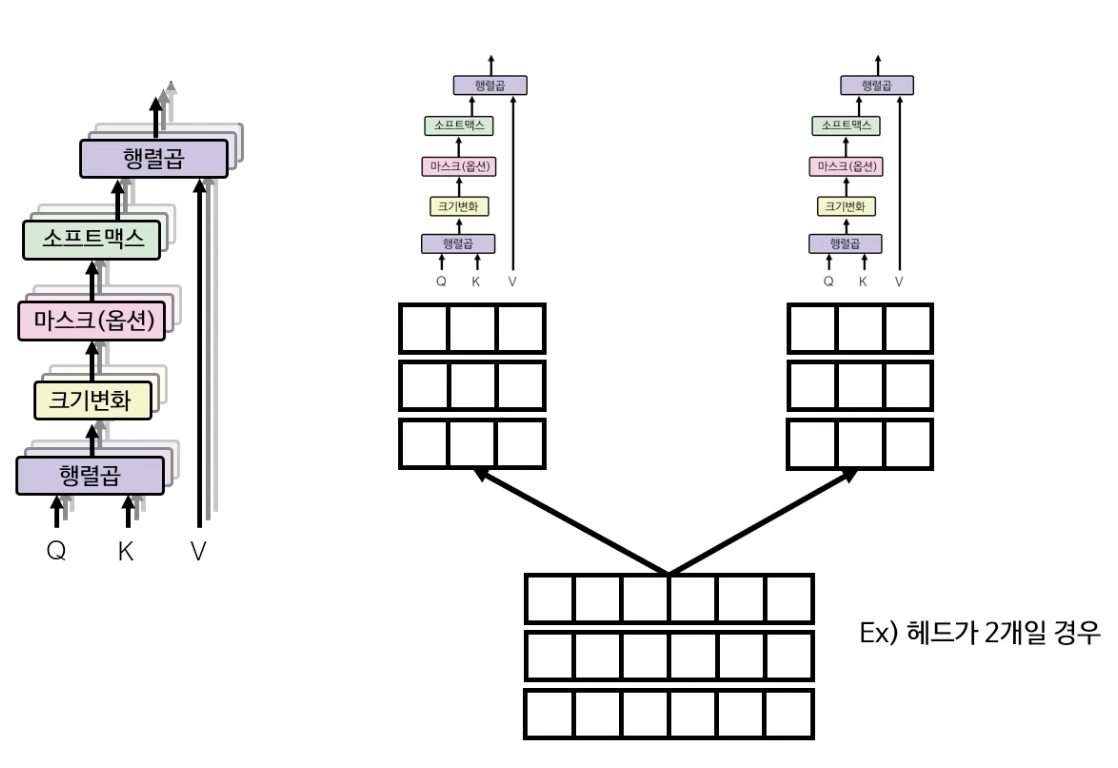
셀프 어텐션을 수행하기 위한 다중헤드 어텐션의 구조는 아래와 같이 생겼다.

우선 처음으로는 아까 구했던 입력+위치 인코딩한 행렬(왼쪽)을 3개로 복사한다. 이 행렬은 Q(Query), K(Key), V(Value) 행렬을 구하기 위해 사용되는데, 각각의 행렬은 무작위로 생성된 각각의 6X6 행렬과 행렬곱을 통해 Q, K, V 행렬을 구한다.

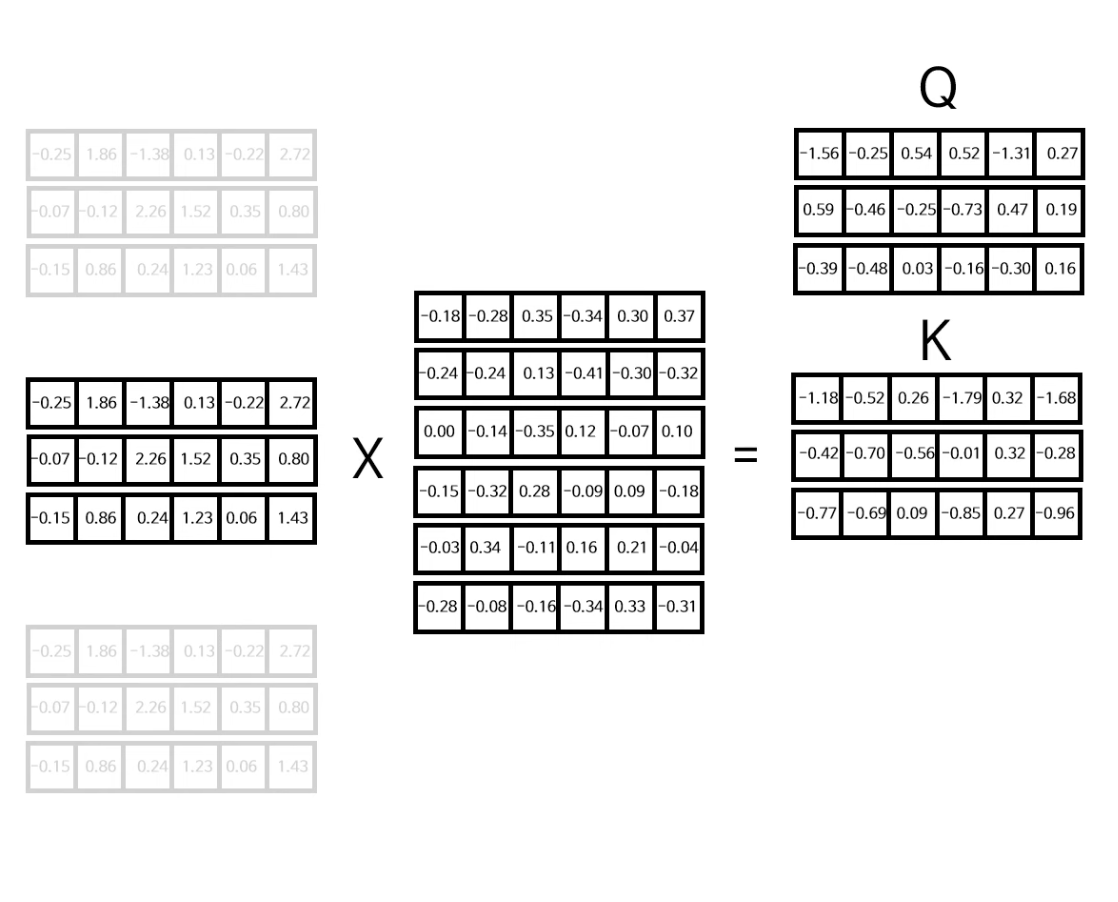
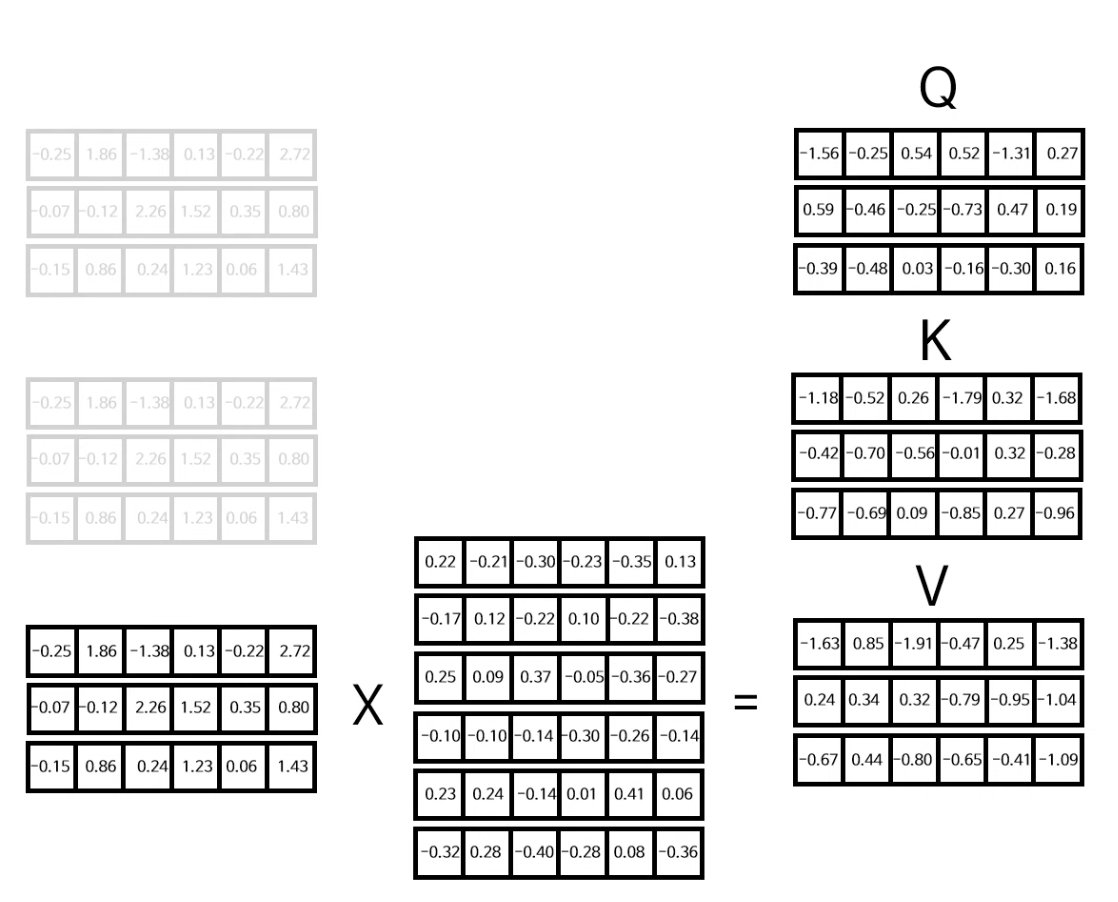
그 후 구한 Q, K, V값을 다중헤드 어텐션 레이어의 입력값에 넣는다.
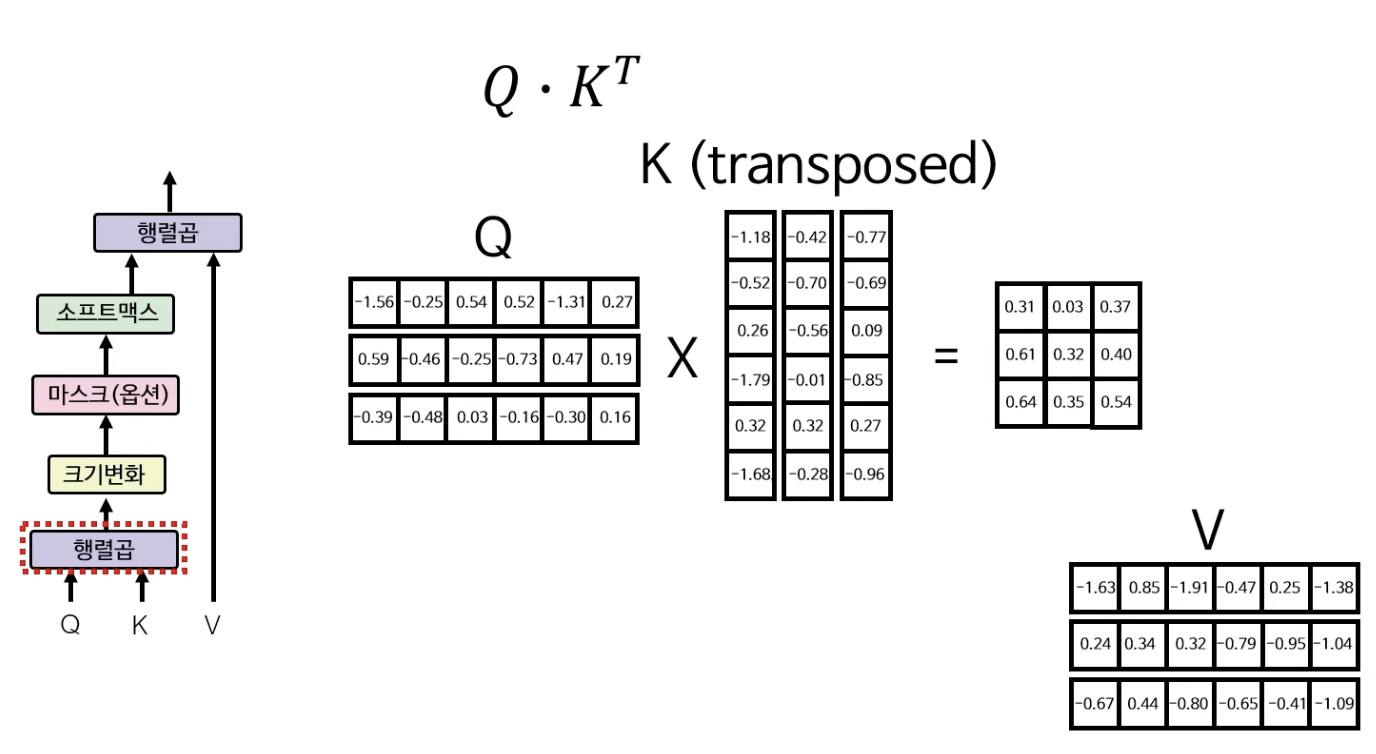
다중헤드 어텐션에서의 첫 레이어에선 Q와 K의 행렬곱이 이뤄진다. $Q * K^T$로 행렬곱을 하여 3X3 행렬을 구해낸다.
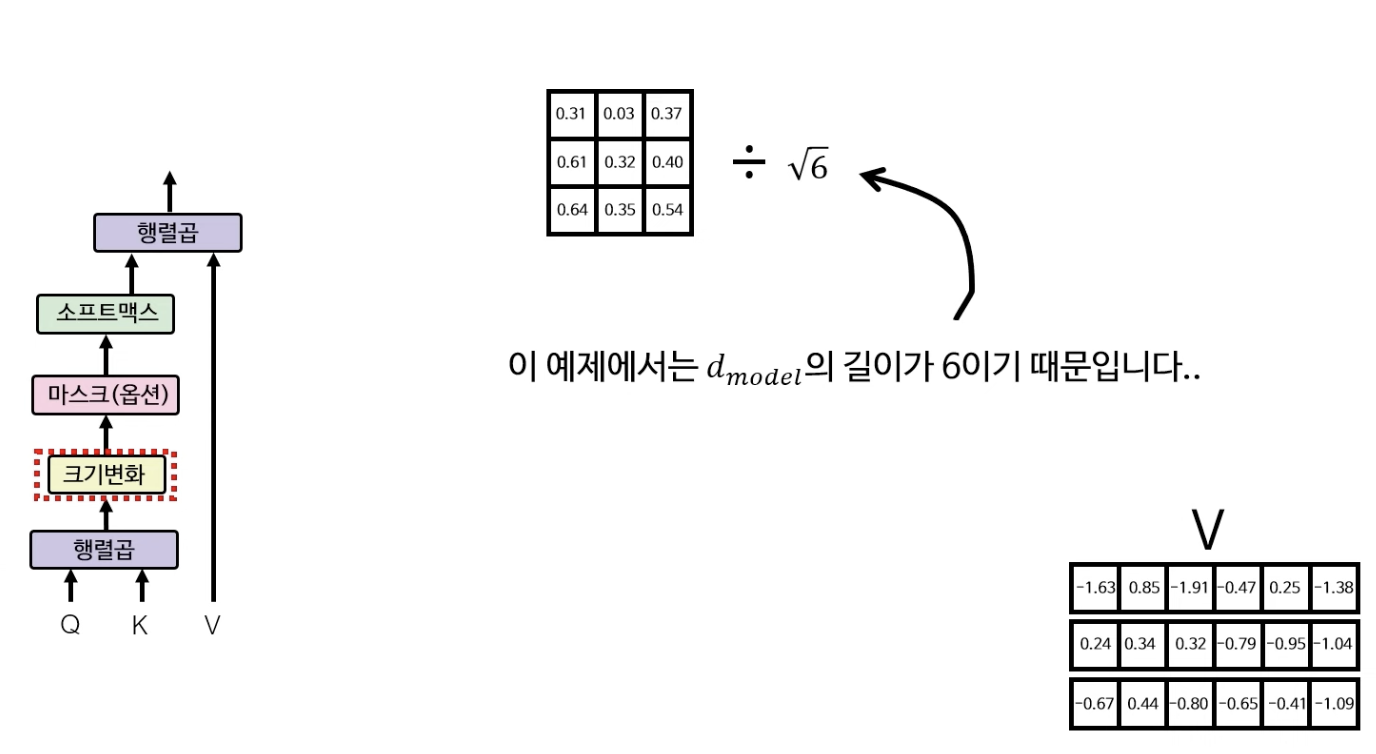
그 다음으로 크기변화(Scale)을 해야하는데, 여기서는 루트 6으로 3X3 행렬의 원소 각각을 나눠준다.
(예시의 $d_{model} = 0$ 이기에 루트 6으로 나눠줌)
(그 다음은 마스크 레이어인데, 마스크 레이어의 경우 인코더에서 사용하지 않기 때문에 인코더 부분에서는 스킵하도록 한다.)
소프트맥스 레이어는 행렬의 값을 0~1 사이의 확률값으로 바꿔주는 역할을 한다.
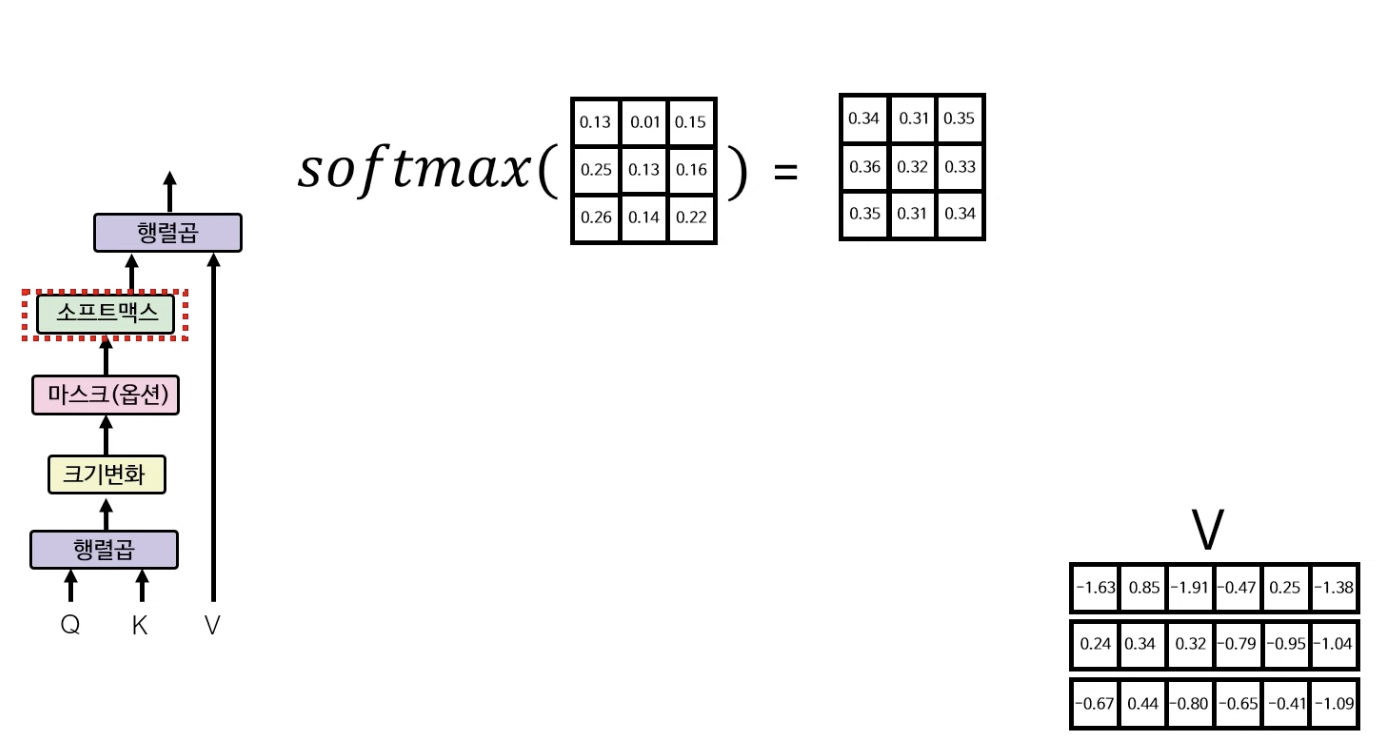
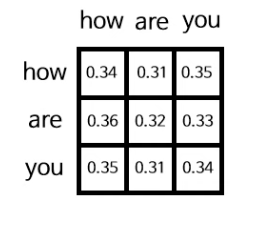
소프트맥스 레이어를 통과하게 되면 아래와 같은 3X3 행렬이 나오게 되는데, 이 행렬은 각각의 단어들이 또 다른 각각의 단어들과 어떤 관계가 있는지를 수치로 보여주는 행렬이다. (how는 are과 0.31(31%)만큼 관련이 있음) 단어 간의 관련이 높을수록 높은 수치를 갖게 된다. 아직은 학습이 안된 상태이기에 수치가 제대로 반영이 되지 않은 상태다.
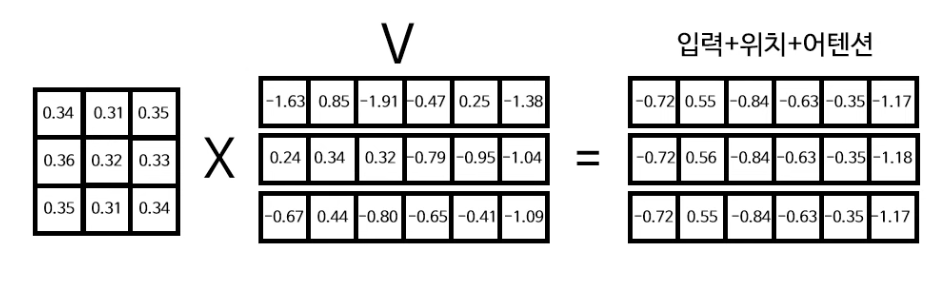
마지막으로 V행렬과 소프트맥스에서 산출된 함수를 행렬곱하여 self-attention이 가미가 된 입력+위치+어텐션 임베딩 행렬을 산출한다.
(3X3 행렬이 어텐션 정보를 포함, V 행렬이 입력+위치 정보를 포함하고 있다고 보면 된다.)
위의 예시에서는 다중 헤드 어텐션이 하나의 헤드만 있을 경우를 가정한 설명이었다면, 실제로는 아래 그림(왼쪽)과 같이 멀티헤드로 어텐션을 취하게 된다. (논문에서는 8개의 헤드를 사용) 만약 2개의 헤드를 이용하여 어텐션을 계산하게 될 경우 Q, K, V의 단계에서부터 헤드의 숫자대로 나누어 self-attention을 각각 계산해 준 다음, 최종 단계에서 다시 산출된 행렬을 concatenate 해준다.
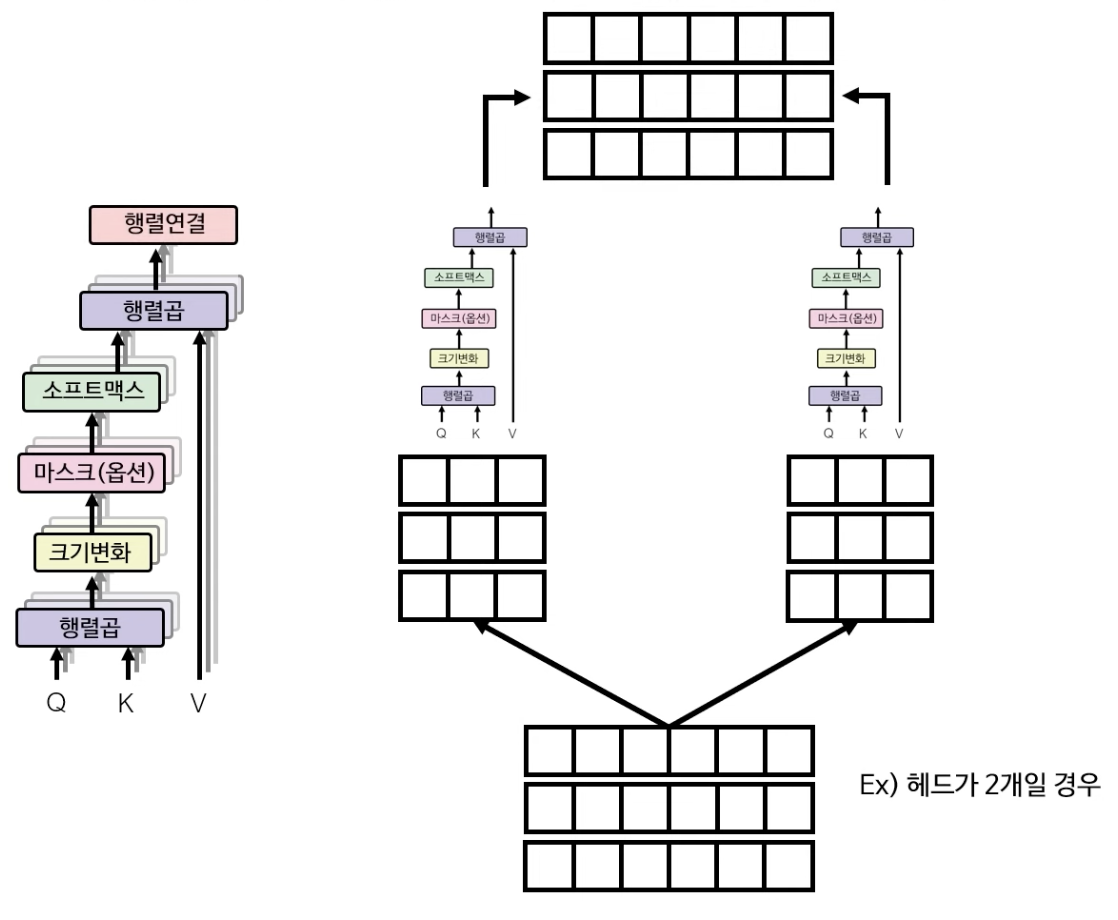
그리고 마지막으로 완전 연결층(fully connected layer) 레이어에서 다중 헤드 어텐션의 최종 output을 계산해낸다.
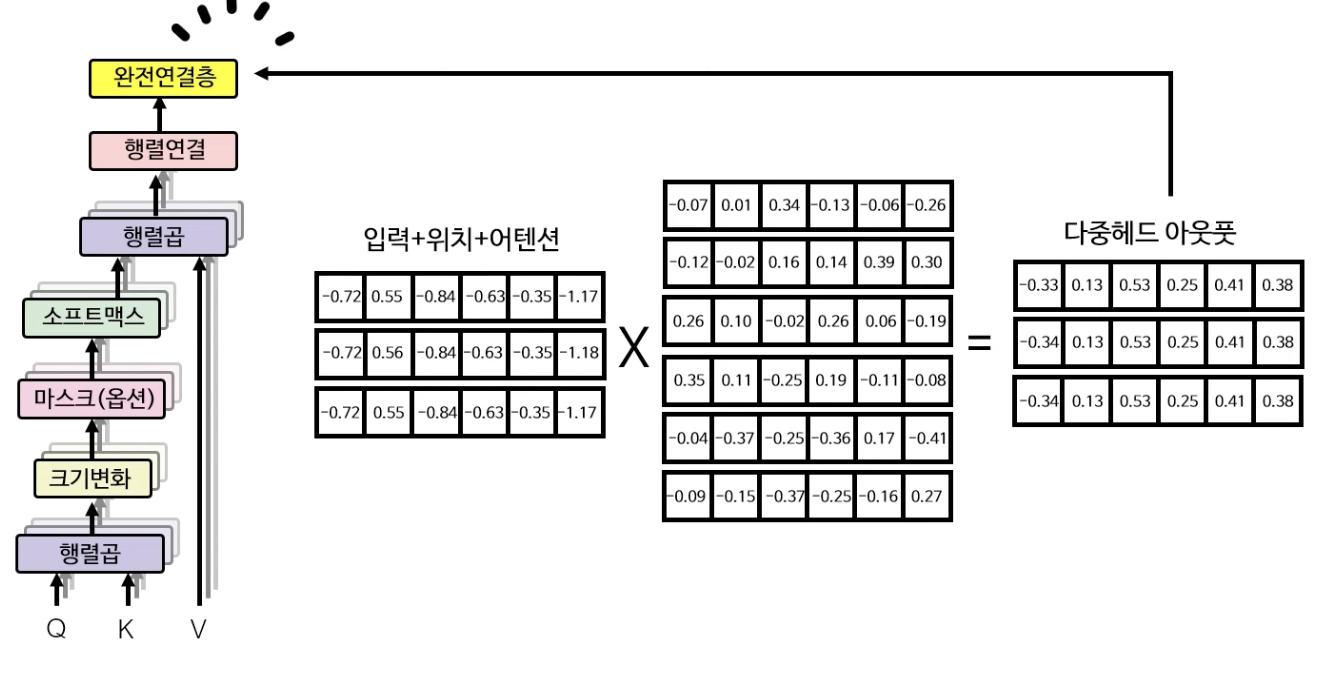
합 & 정규화 레이어
그 다음으로 합 & 정규화 레이어를 살펴보자.
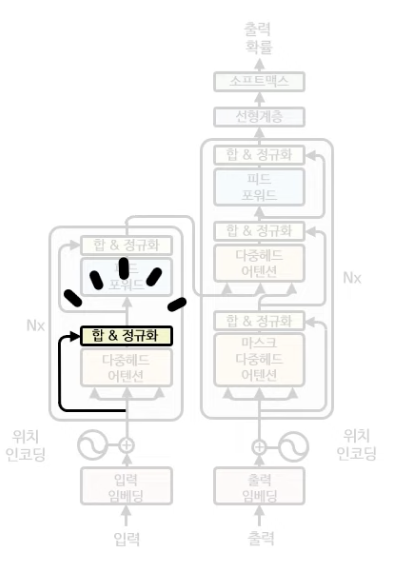
합 & 정규화 중에 합 레이어는 다중헤드 아웃풋 행렬과 처음 입력+위치 임베딩 행렬을 더하는 과정이다. 이는 ResNet에서 도입된 Skip-connection 단계인데, 학습 기울기 소실 문제 완화, 기존 정보(입력 + 위치 임베딩) 보존 및 새로운 정보 가미 등 여러 효과를 낼 수 있다는 장점이 있다.
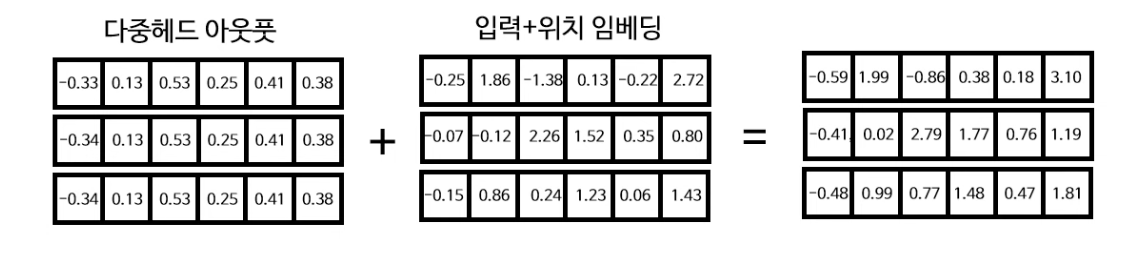
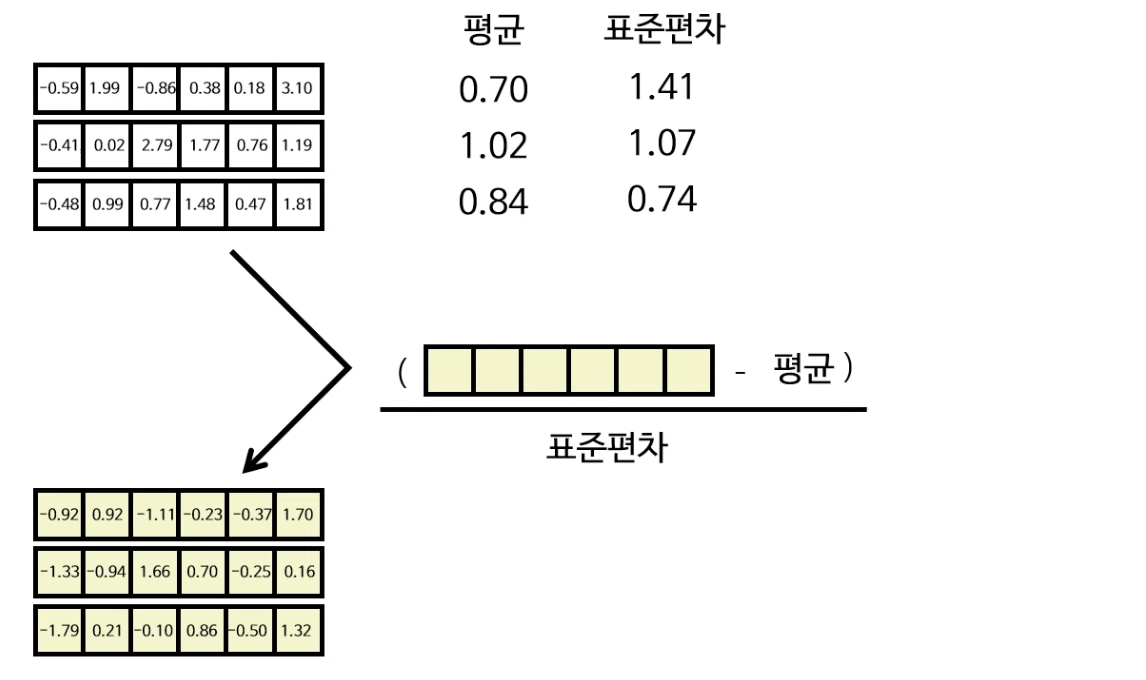
다음 합 & 정규화 중 정규화 레이어는 방금 합 단계에서 구한 행렬을 각 열 별로 평균과 표준편차를 계산한 뒤 정규화 공식을 이용하여 각 열별로 정규화를 진행하여 정규화 행렬을 구한다.
피드 포워드 레이어
다음으로 피드 포워드 레이어 단계를 살펴보자.
피드포워드 레이어는 2개의 층으로 이루어진 ReLU()를 활성화 함수로 사용하는 단순 신경망 구조를 의미한다.
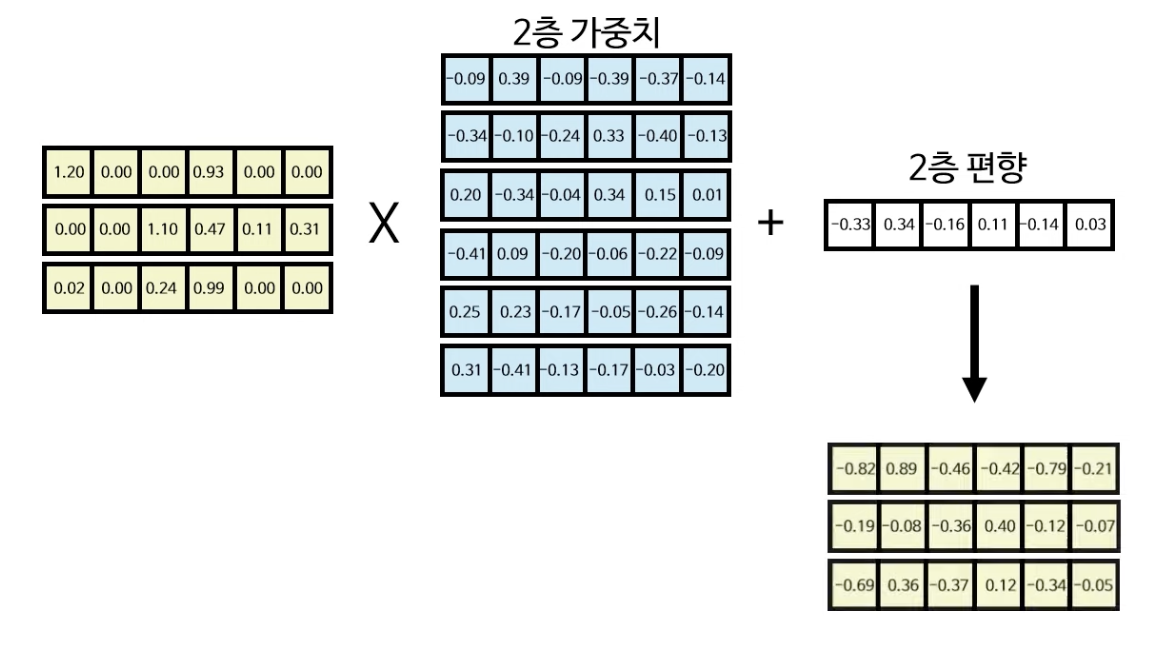
먼저 방금 구한 정규화 행렬을 1층 가중치와 곱하고, 1층 편향과 더한 다음 ReLU 활성화 함수를 적용해준다. (음수 부분은 0이 될 것)
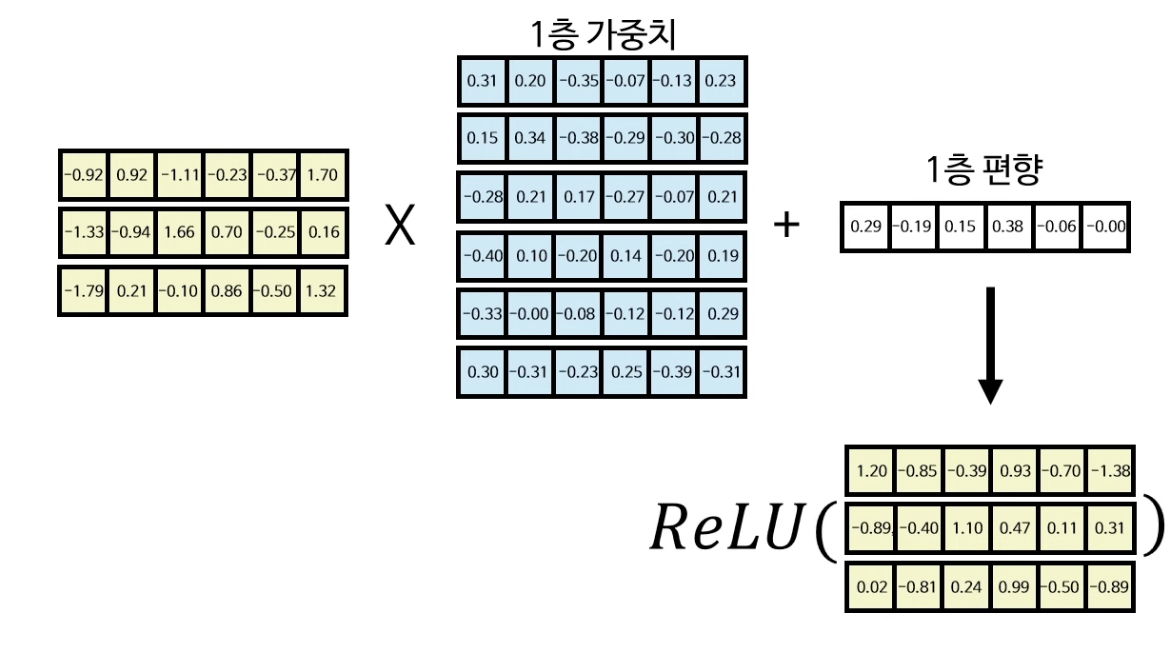
1층 레이어에서 구한 행렬을 2층 가충치와 곱하고 2층 편향과 더해주면 피드포워드 레이어의 아웃풋을 산출해낼 수 있게 된다.
그렇다면 우리는 피드포워드 레이어를 왜 넣는지에 대한 근본적인 문제를 살펴볼 필요가 있다. 피드포워드 레이어를 넣는 이유는 다층 신경망의 특성에서 알 수 있듯, 비선형성을 증가시켜 네트워크 자체가 데이터를 처리하고 분별할 수 있는 능력을 증가시키는데 있다. (영상의 예시에서는 피드포워드 레이어를 2층 신경망으로 구성하여 사용하였지만, 이보다 . 더 많은 층을 사용해도 무방하다.)
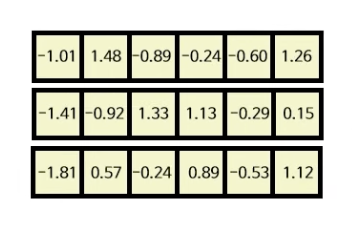
그 다음 마지막으로 피드포워드 레이어에서 나온 최종 아웃풋을 다시 이전에 반복했던 합 & 정규화 레이어로 반복해주면, 인코더의 전체 아웃풋이 산출이 되게 된다.
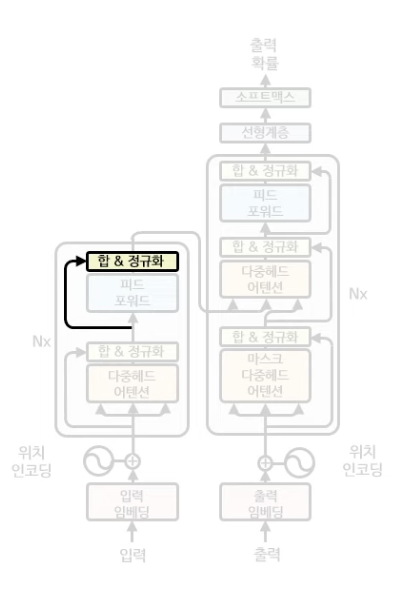
Decoder(디코더)
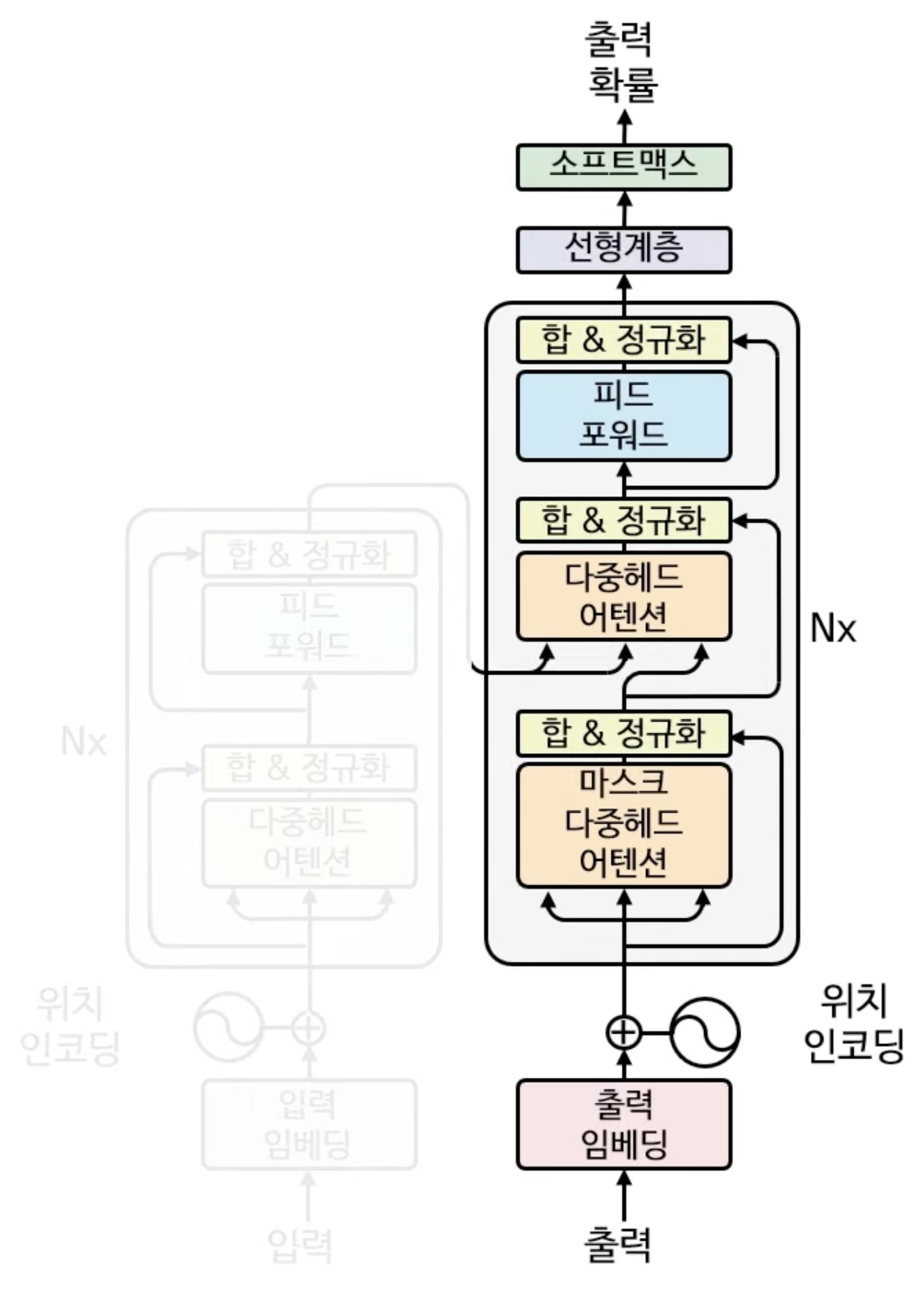
트랜스포머 학습 과정에서 가장 먼저하는 것은 인코더와 같이 출력(단어) 인코딩과 위치 인코딩을 하는 것이다. 단어 인코딩과 위치 인코딩은 인코더 때와 똑같은 방식으로 이뤄진다. (인코더 출력 + 위치 임베딩 참고)
마스크 다중헤드 어텐션
다중헤드 어텐션 부분도 인코더와 크게 다를게 없다. 그러나 한가지 짚고 넘어가야 하는 것이 존재하는데, 바로 그것이 마스크(옵션)의 단계이다.
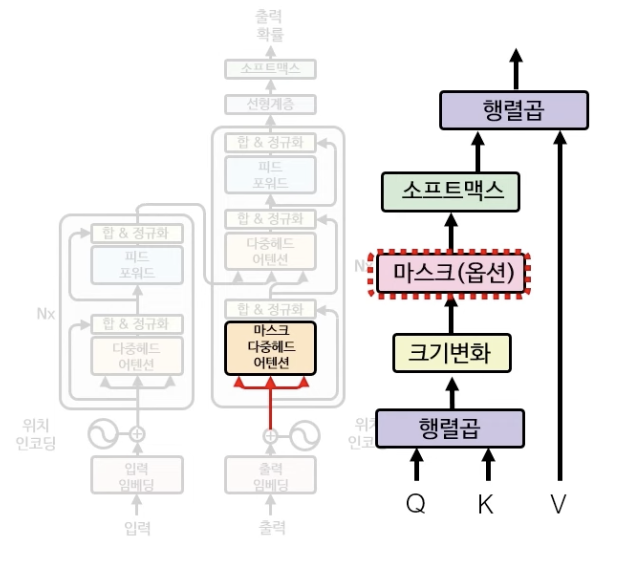
원래 트랜스포머 디코더의 목적은 출력 단어 시퀸스를 생성해내는 것이다. 인코더의 경우는 입력 문장 전체의 의미를 파악해야 하기 때문에 전체 단어들의 관계를 다 파악해야 할 필요가 있다.

그러나 디코더의 경우는 출력 문장을 한 단어씩 출력하는 것이 목적이기 때문에, 아직 출력되지 않은 단어에 Attention을 줄 수 없는 것이 당연하다. 때문에, 트랜스포머의 디코더 학습 과정에 이러한 특성을 반영하여, 특정 단어를 기준으로 미래에 나오는 단어는 가려서 계산에 영향을 주지 않도록 하는 것이 핵심이다.

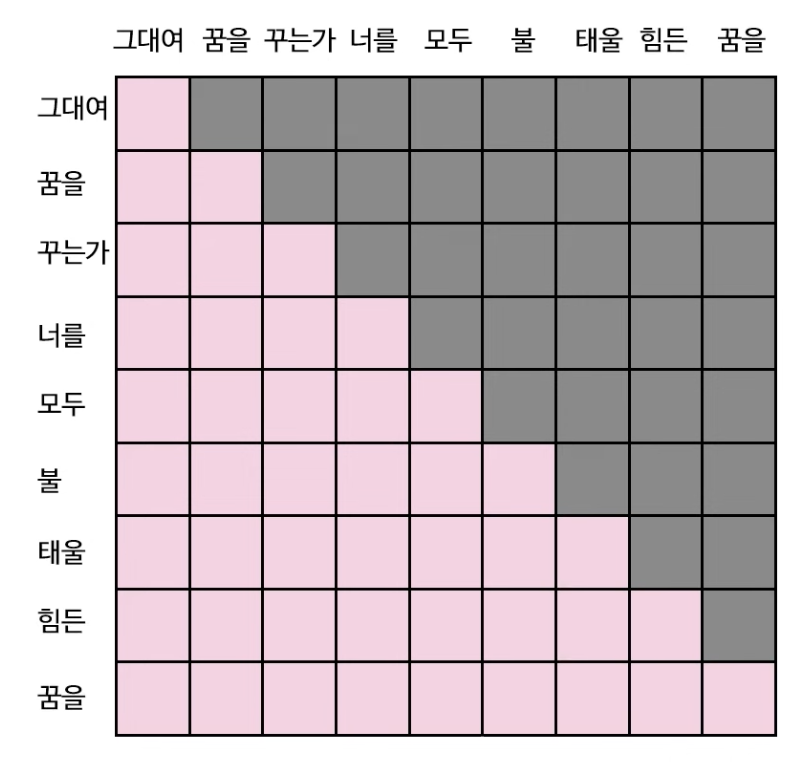
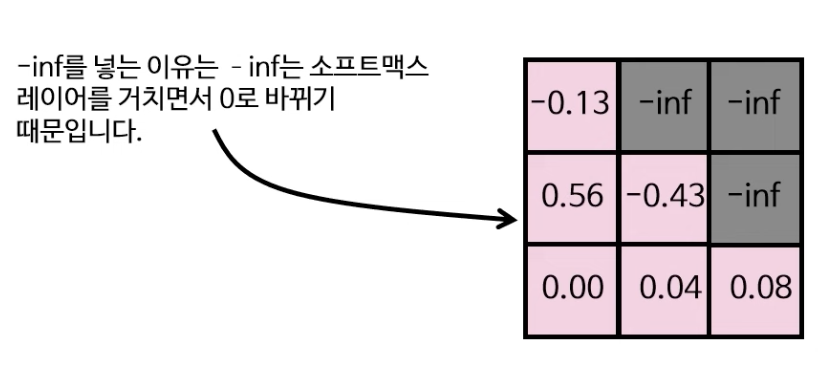
때문에 이런 마스크 알고리즘을 어텐션 행렬(행렬곱 -> 크기 변화 통한 출력)에 적용하면, 아래와 같이 변환할 수 있게 된다.
그 후 과정은 인코더의 다중 헤드 어텐션과 같다.
다중헤드 어텐션
디코더의 다중헤드 어텐션은 인코더와 작동 방식이 같지만, 입력값만 조금 차이가 난다.
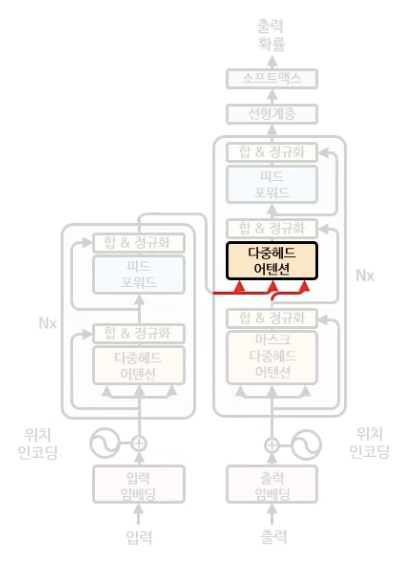
2번째 다중헤드 어텐션에서 K, V의 값은 인코더의 최종 아웃풋을 각각의 6X6 행렬로 곱한 값을 입력으로 하고 Q의 값은 방금 전 구한 디코더의 행렬을 6X6 행렬로 곱한 값을 입력으로 한다.
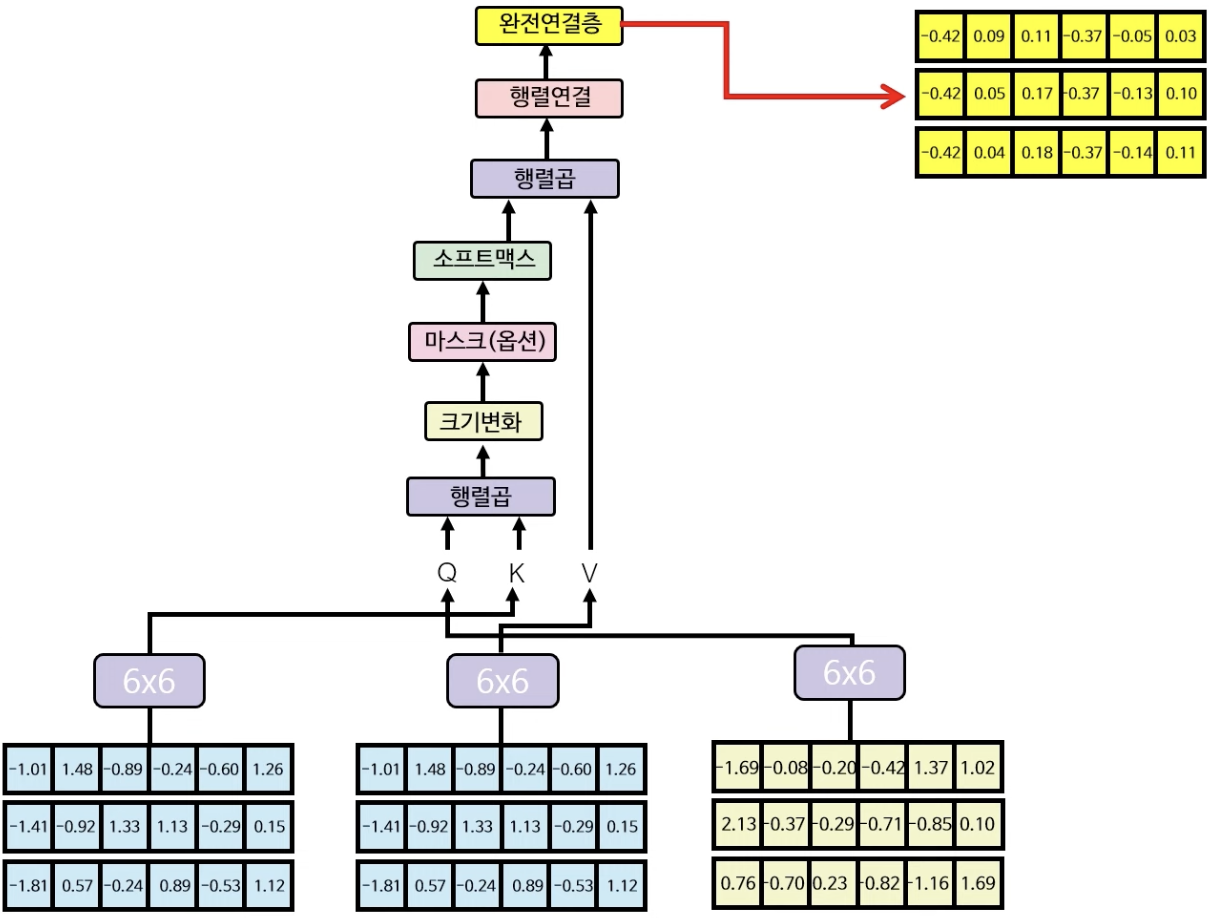
그 결과 다중헤드 어텐션의 3X6(노란색) 행렬이 나오게 된다.
(그 다음 합 & 정규화, 피드 포워드 레이어는 방금 전 연산과정과 동일하므로 생략한다.)
선형계층 & 소프트맥스
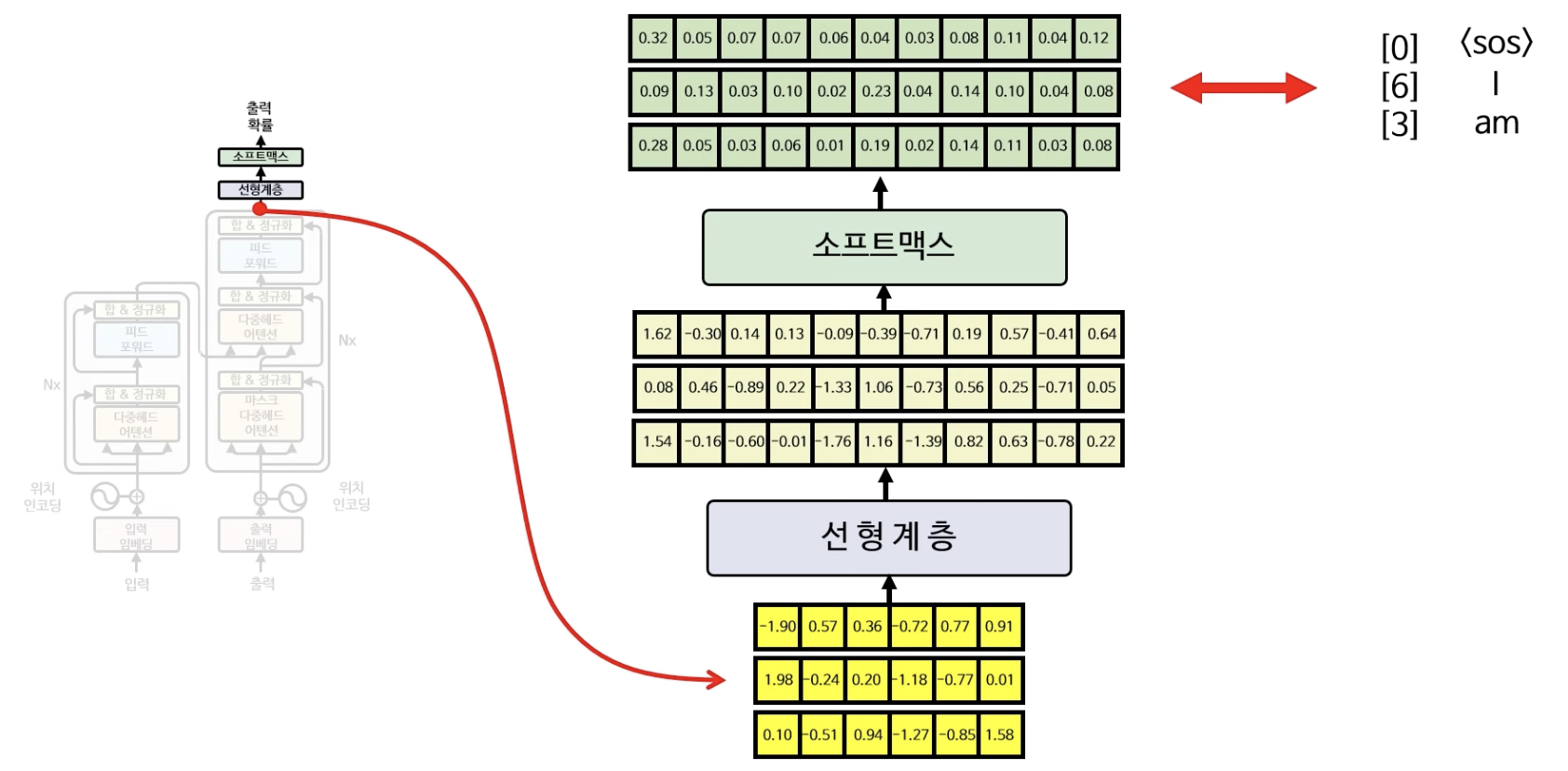
트랜스포머의 마지막 단계는 선형계층과 소프트맥스 계층의 최종 아웃풋을 구하는 단계다.
우선 디코더의 축약된 아웃풋 행렬을 선형계층 레이어에 통과시켜서 기존 vocabulary 길이(해당 예시에서는 11)만큼 다시 펼치고 소프트맥스 레이어를 컬쳐 최종 출력값 행렬을 산출한다. 그 다음 최종 정답인 0, 6, 3과 비교하여 손실함수(ex. cross-entropy)와 역전파를 이용하여 모든 레이어들의 가중치값들을 업데이트 해가는 것이 트랜스포머의 최종 학습 과정이라고 할 수 있다.
Reference
https://www.youtube.com/watch?v=p216tTVxues
'Analytics' 카테고리의 다른 글
| [RecSys] 추천시스템 전반적 개요 정리 (3) | 2024.09.29 |
|---|---|
| [Causal Inference] 메타러너 (1) | 2024.09.28 |
| [Causal Inference] 이질적 처치효과 (2) | 2024.09.24 |
| [Causal Inference] 성향점수 (5) | 2024.09.22 |
| [ML/DL] ELMo: Embeddings from Language Models (4) | 2024.09.20 |