

이전 글과 이어지는 내용입니다.
https://baram1ng.tistory.com/48
[Causal Inference] 이질적 처치효과
이전 글과 이어지는 내용입니다.https://baram1ng.tistory.com/47 [Causal Inference] 성향점수이전 글과 이어지는 내용입니다.https://baram1ng.tistory.com/45 [Causal Inference] 유용한 선형회귀이전 글과 이어지는 내
baram1ng.tistory.com
이질적 효과 프레임워크에서 이산형, 연속형 처치에 각각 추정하고 싶은 CATE는 아래와 같다.
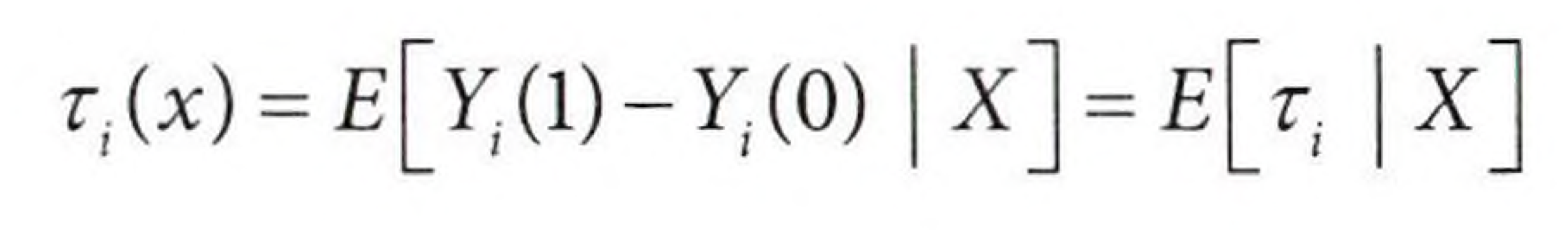
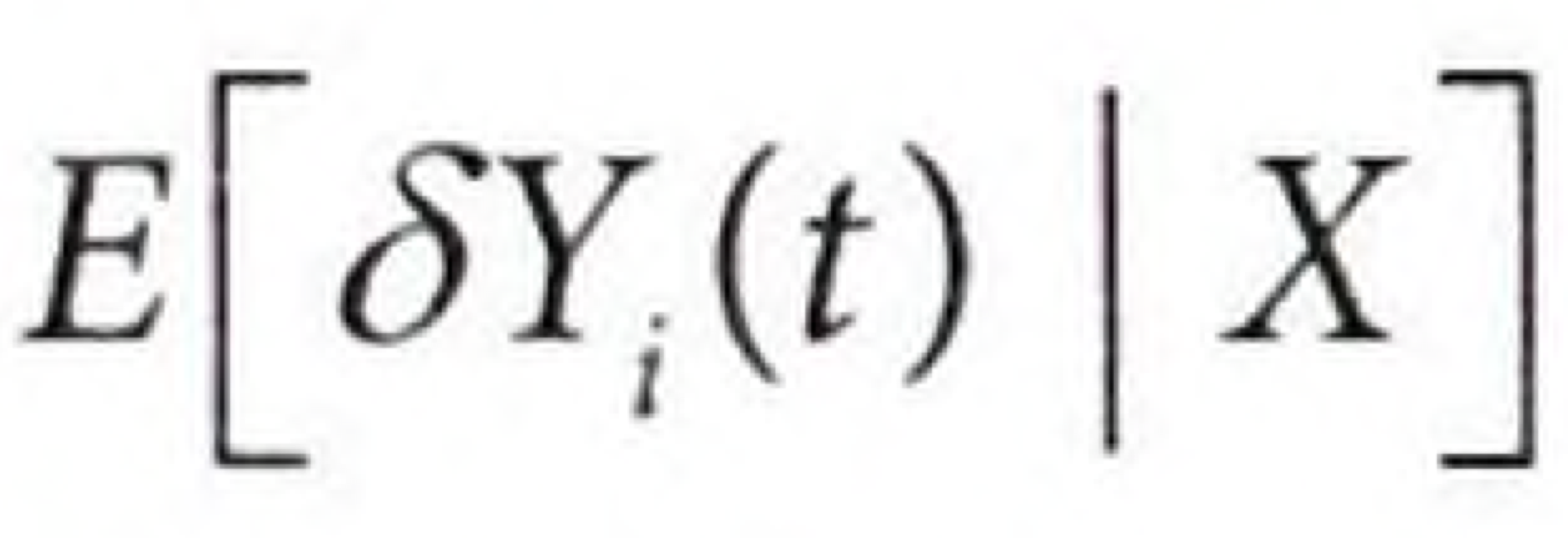
이는 모든 대상에게 처치를 할 수 없고 처치의 우선순위를 정해야 하는 경우에 매우 유용하다.
이전 장에서는 회귀분석을 사용하여 CATE 추정값을 구했다면, 이번 장에서는 머신러닝 알고리즘을 통해 CATE 추정값을 구해보고자 한다.
메타러너는 예측 머신러닝 알고리즘을 활용하여 처치효과(τ)를 추정하는 간단한 방법이다.
이산형 처치 메타러너
예시를 통해 차근차근 살펴보자. 예를 들어 온라인 소매업체 마케팅 팀에서 어떤 고객이 마케팅 이메일을 잘 받는지 파악하는 상황을 가정하고자 한다. 우리는 이메일이 고객의 미래 구매량에 미치는 조건부 처치 효과를 추정하고자 한다.
아래는 사용 데이터다.
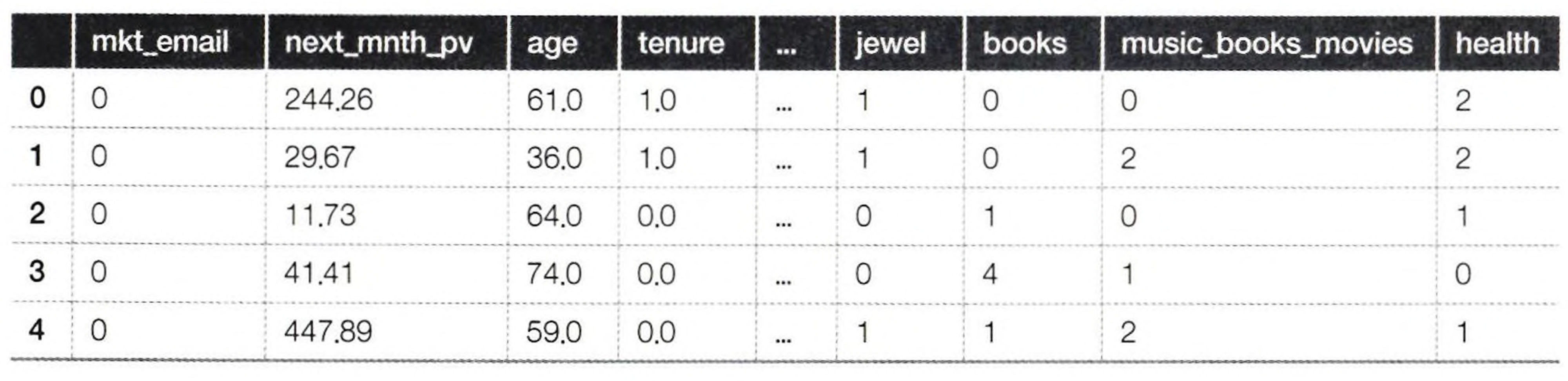
- mkt_email: 이메일 발송 여부(처치 변수)
- next_mnth_pv: 이메일을 받은 후 한 달 후의 구매금액(결과 변수)
인과추론 라이브러리가 여럿 존재하지만 여기서는 밑바닥부터 만드는 방법을 살펴본다. 패키지 예시로 마이크로소프트의 econml과 우버의 causalml 라이브러리가 존재한다.
T 러너
범주형 처치를 다룰 때 메타러너로 T러너를 사용한다.
T러너는 잠재적 결과 $Y_t$를 추정하기 위해 모든 처치에 대해 하나의 결과 모델 $μ_t(x)$를 적합시킨다. 이진 처치에서는 추정해야 할 모델이 두 개뿐이므로 T러너라고 불린다.

위 모델을 만들면 아래와 같이 CATE를 추정할 수 있다.
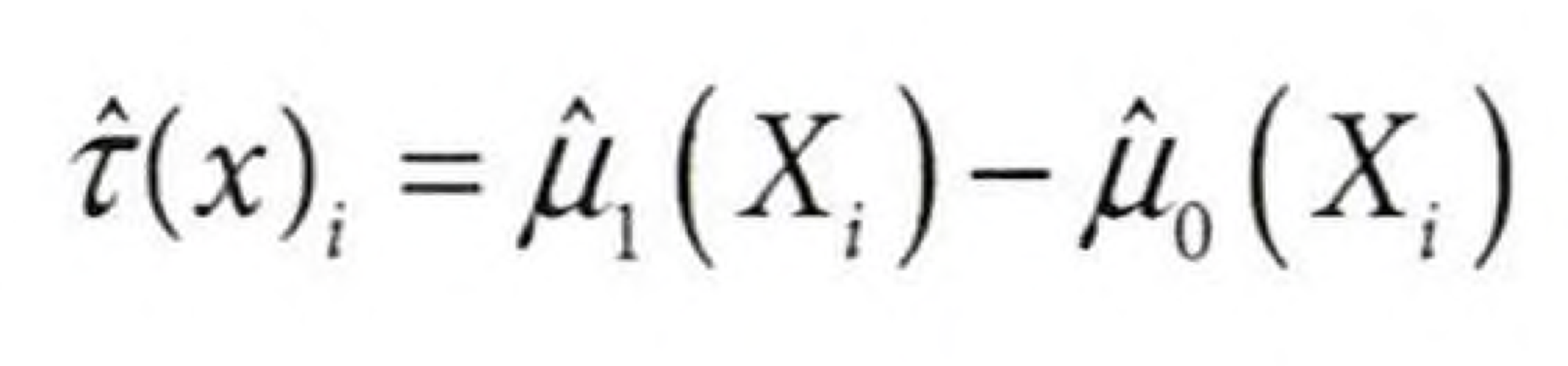
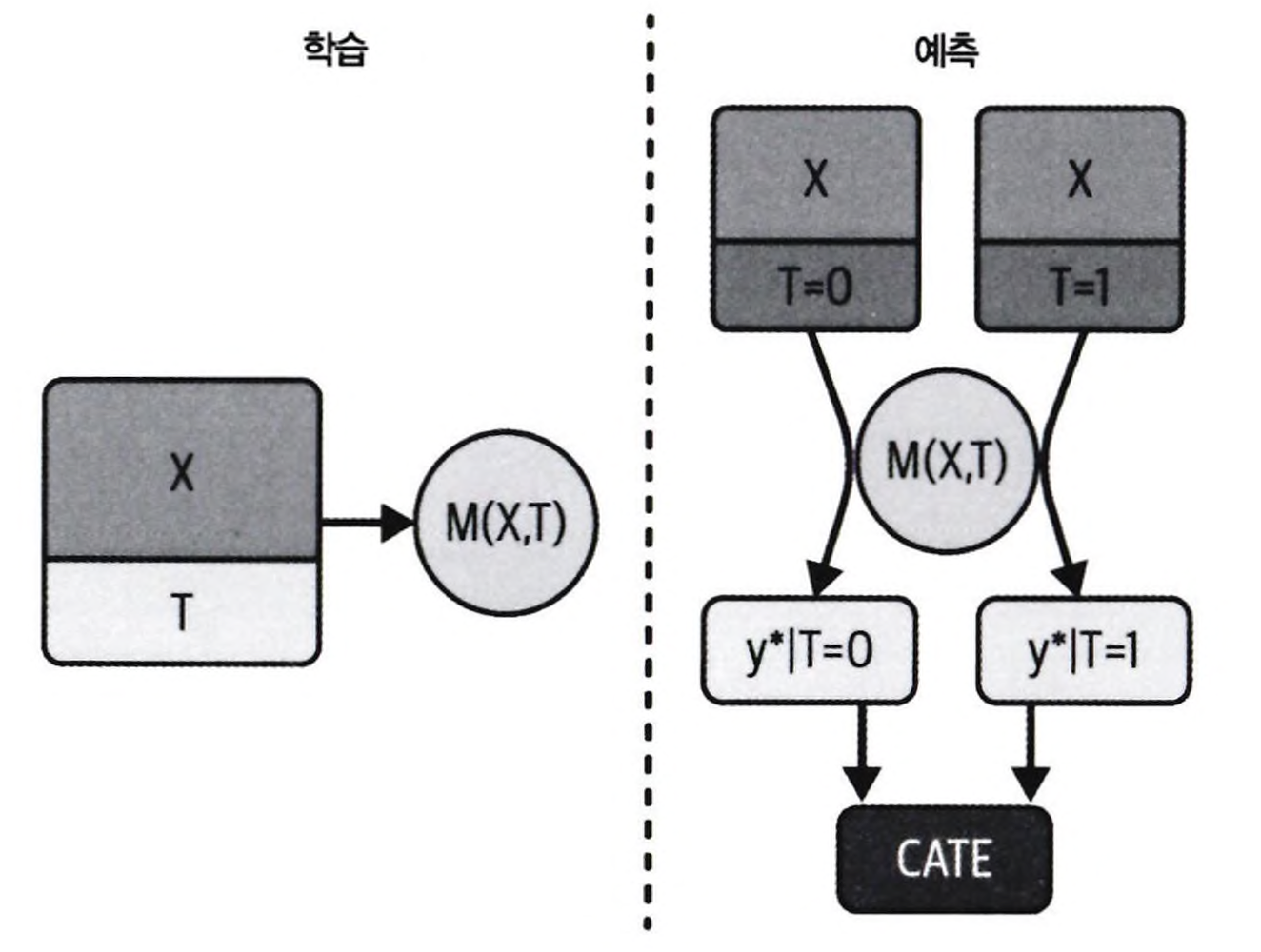
아래는 T러너에 대한 다이어그램이다. 러너가 각자 $T=1$과 $T=0$에서 머신러닝 모델을 학습한다. 예측 시점에 두 모델을 모두 사용하여 실험군과 대조군의 차이를 추정한다.

(코드는 생략한다. 코드가 궁금한 사람들은 https://github.com/CausalInferenceLab/Causal-Inference-with-Python/blob/main/causal-inference-for-the-brave-and-true/21-Meta-Learners.ipynb 에 방문하여 확인하길 바란다.)
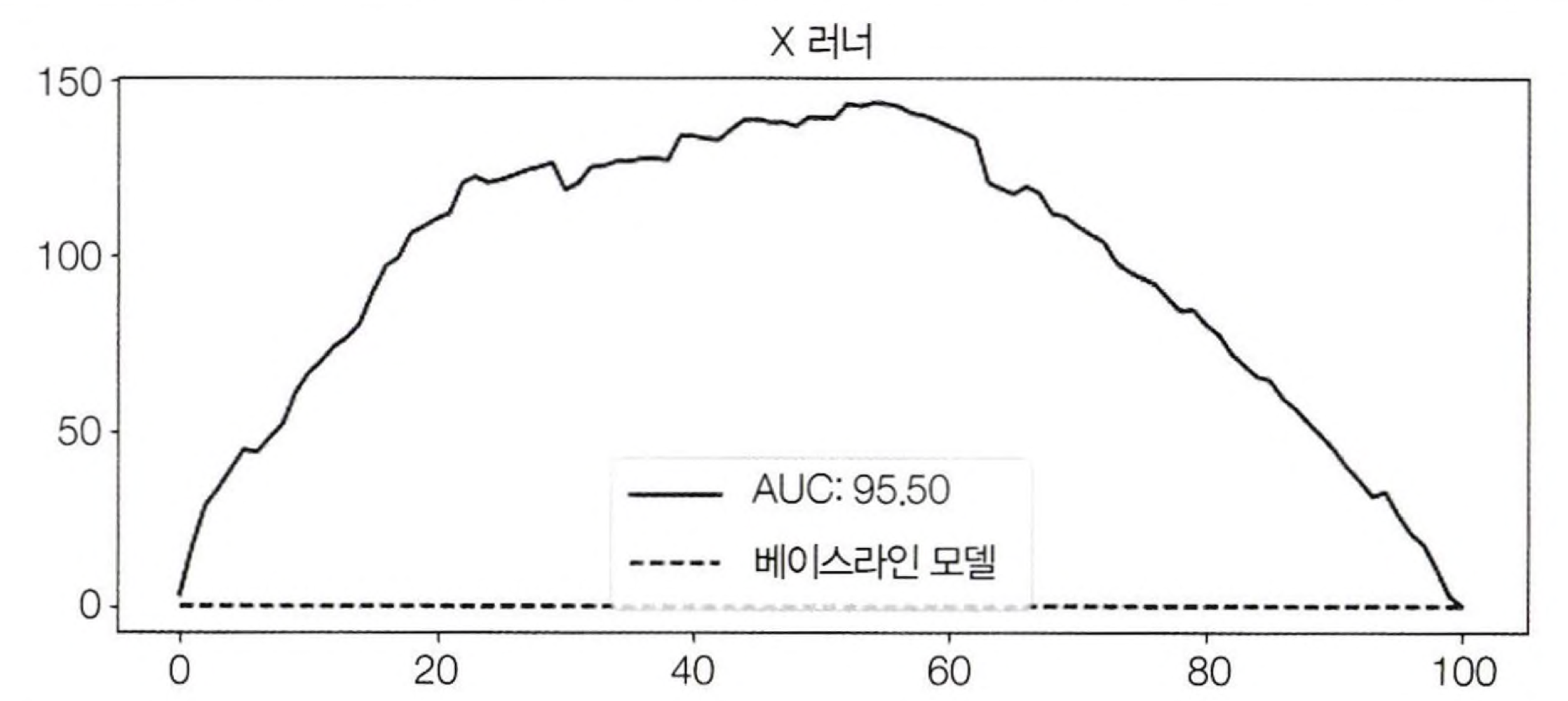
우선 $T = 0$과 $T = 1$에 대한 LGBRegressor를 학습시키고 그에 대한 predict를 계산한 후 빼서 CATE를 예측해보자. 아래는 상대 누적 이득 곡선과 AUC를 이용하여 모델을 평가한 것이다. (처치효과가 가장 높은 고객부터 가장 낮은 고객을 올바르게 정렬했는지에만 관심있는 평가법)
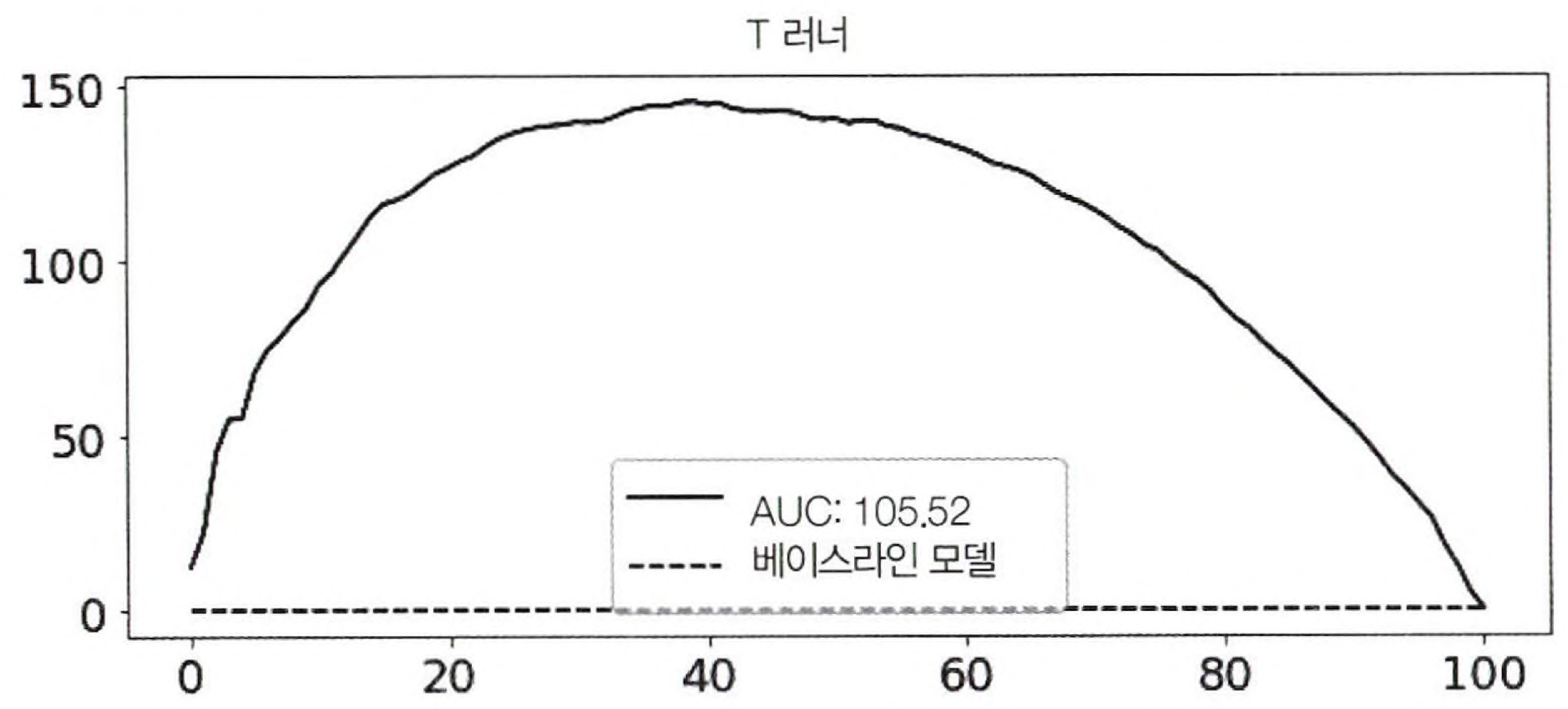
사진을 보면 T러너는 CATE에 따른 고객을 잘 정렬할 수 있는 것으로 보인다.
일반적으로 T러너는 단순한 모델이기에 처치가 이산형으로 주어진 상황일 때 처음 시도하기가 좋다. 그러나 상황에 따라 정규화 편향이 발생하기가 쉽다.
예를 들어 대조군($T=0$)은 많고 실험군($T=1$)은 매우 적은 상황을 생각해보자. (처치에 큰 비용이 적용되는 상황)
데이터가 처치 받은 관측값이 그렇지 않은 관측값보다 매우 적은 경우, 과적합을 피하기 위해 $μ_1$ 모델은 단순해질 가능성이 크다. 반면 $μ_0$ 모델은 더 복잡해질 수 있지만, 데이터가 풍부하기 때문에 과적합을 방지할 수 있다. 그러나 중요한 것은 두 모델에 동일한 하이퍼파라미털르 사용하더라도 이런 상황이 발생할 수 있다는 것이다.
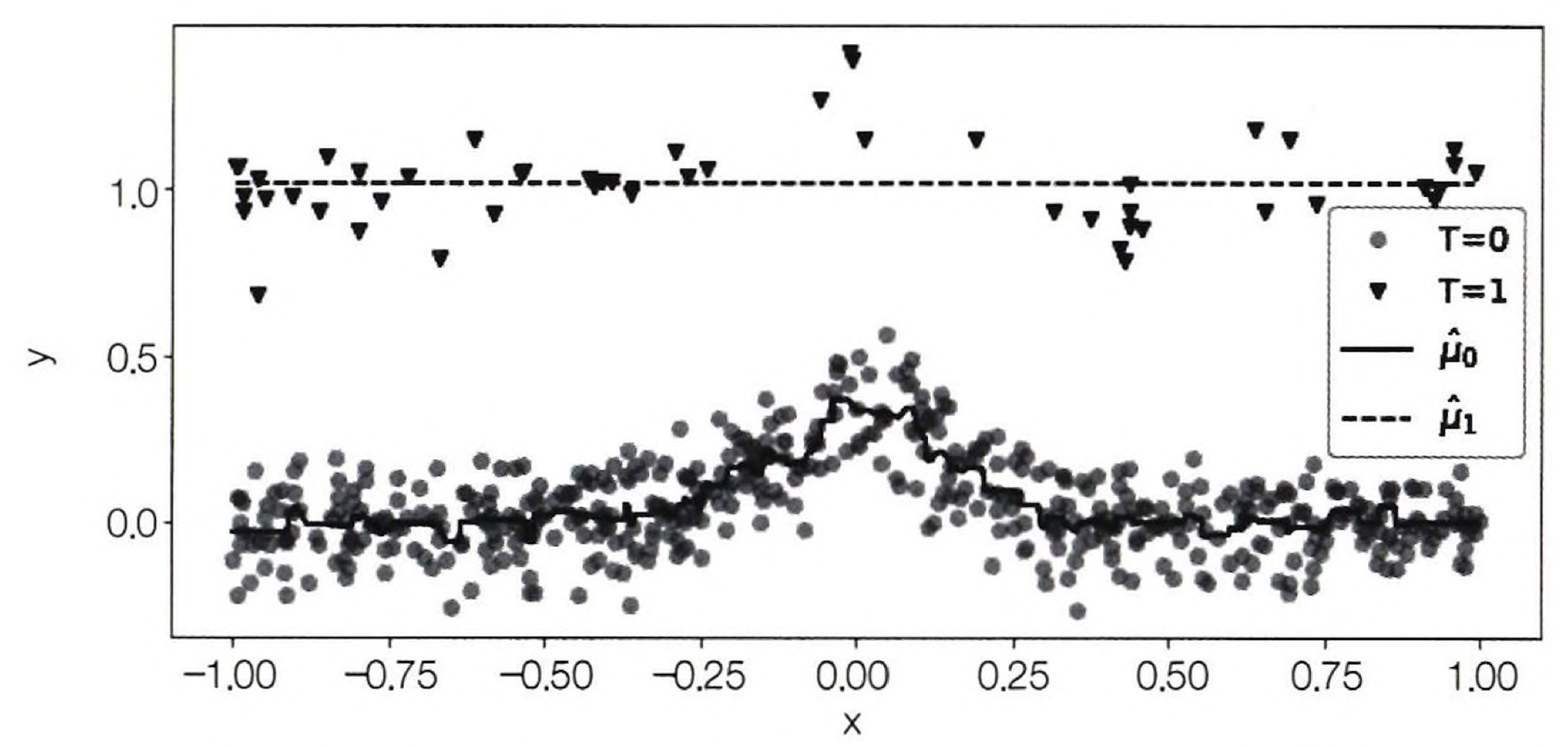

많은 머신러닝 알고리즘은 데이터가 적을 때 자체적으로 정규화한다. 자기 정규화는 머신러닝 관점에서 많은 의미가 있다. 데이터가 적으면 단순한 모델을 사용해야 한다. 해당 예시에서 두 모델 모두 각각 표본 크기에 최적화되어 예측 성능이 굉장히 좋다. 그러나 CATE를 사용하여 $τ = μ_1(X) - μ_0(X)$를 계산하면 $μ_0(X)$의 비선형성과 $μ_1(X)$의 선형성 차이 때문에 비선형성 CATE가 된다. 그러나 예시에서 실제 CATE는 1로 일정하기 때문에 이는 잘못된 결과라고 볼 수 있다.
결론적으로, 표본이 많은 대조군 모델에서는 비선형성을 포착할 수 있지만, 작은 표본을 가진 실험군에서는 정규화되므로 비선형성을 포착할 수 없게 되는 경우가 있다. 이 문제를 해결하기 위해 X러너가 등장한다.
X러너
X러너는 두 단계로 구성되며 성향점수 모델이 존재한다.
- 첫 번째 단계
- 표본을 실험군과 대조군으로 나누고 각 그룹에 모델을 적합시킨다.

- 두 번째 단계
- 여기서 T러너와의 차이점이 존재하는데, 앞서 적합된 모델을 사용하여 누락된 잠재적 결과를 추정한다.
- 그 다음 추정된 효과를 예측할 두 개의 추가 모델을 적합시킨다. (대조군과 실험군에서 CATE를 잘 근사하기 위함)
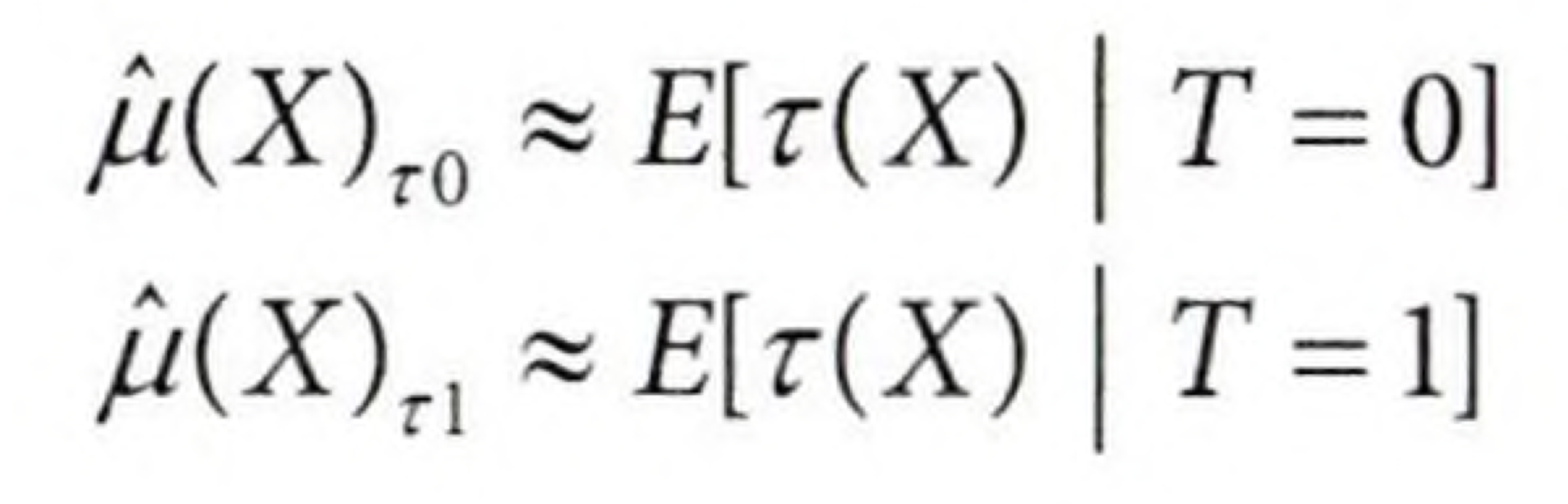
아래 그래프에서 대조군에 대한 데이터가 더 많지만, $τ(X, T = 0)$이 잘못되었음을 확인할 수 있다. 이는 매우 작은 표본에 적합된 $μ_1$을 사용하여 모델이 구성되었기 때문이다. 반대로 $τ(X, T = 1)$은 정확할 것이다. 왜냐하면 $μ_0$을 사용하여 적합했기 때문이다.
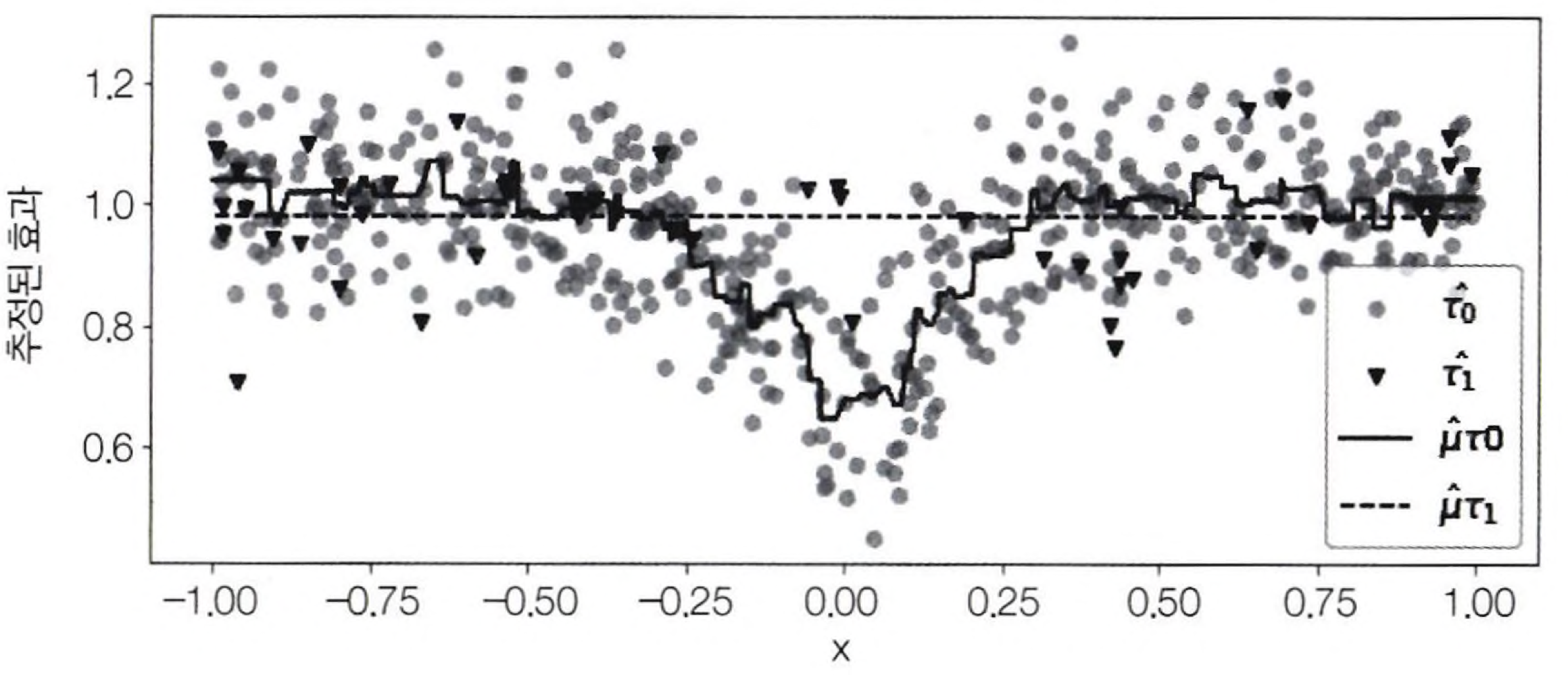
결론적으로 하나의 모델은 처치효과를 잘못 대체했기 때문에 부정확하고 다른 하나의 모델은 그 값을 올바르게 대체했기에 정확하다. 이제 두 모델을 결합하는 방법이 적용되는데, 정확한 모델에 더 많은 가중치를 주는 방법으로 적합이 이루어진다.
우리는 가중치 부여에 성향점수 모델을 활용하여 아래와 같이 모델을 적합할 수 있다. 처치 받은 대상이 매우 적기에 성향점수가 매우 작아 잘못된 CATE 모델 $μ(X)_{t1}$에 매우 작은 가중치를 부여하고 올바른 CATE 모델에 더 많은 가중치를 부여한다.
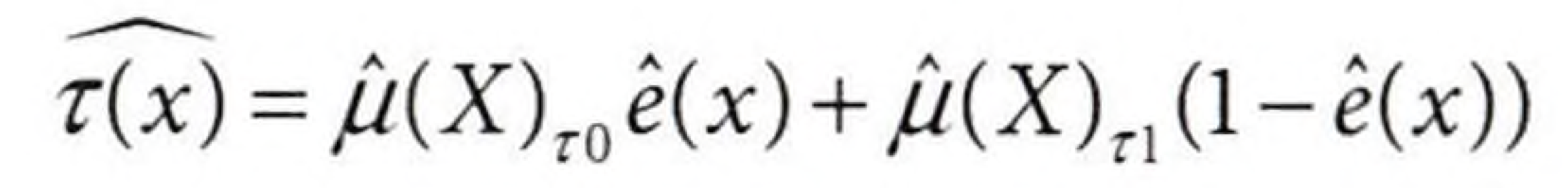
아래는 X러너에 추정된 CATE와 각 데이터 포인트에 할당된 가중치를 보여준다. 이를 통해 T러너보다 X러너가 비선형성에서 잘못 추정된 CATE를 보정하는데 더 나은 성능을 보이는 것을 확인할 수 있다.

아래는 X러너에 대한 다이어그램으로 X러너가 두 가지 단계에서 머신러닝 모델과 성향점수 모델을 학습하는 것을 확인할 수 있고 예측 시에는 두 번째 단계의 모델과 성향점수 모델만 활용하는 것을 볼 수 있다.

도메인 적응 러너: X 러너이지만, 성향점수 모델을 사용하여 $μ_t(X)$를 추정하되 가중치는 $1/P(T=t)$로 설정하는 방법
누적 이득 곡선의 관점에서 X 러너의 성능을 살펴보면 아래와 같다. 해당 예시에서는 실험군과 대조군의 표본 크기가 충분히 크기 때문에 T러너와의 차이가 보이지 않지만, 실험군과 대조군의 표본 크기가 차이 난다면 X 러너의 장점이 발현되는 것을 확인할 수 있을 것이다.
연속형 처치 메타러너
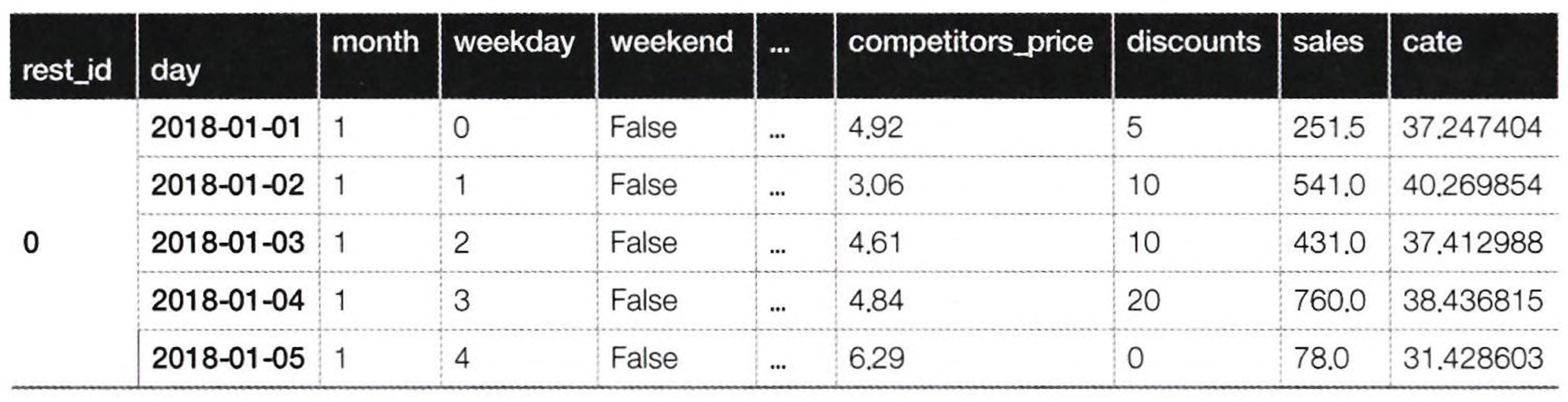
연속형 데이터에서의 처치 메타러너를 예시를 통해 알아보자. 레스토랑에서 무작위로 할인을 제공하는데 언제 더 많은 할인을 제공하는지 알고 싶어하는 상황을 가정하자. 아래는 해당 데이터다. (목표는 CATE 예측)

- discounts: 할인 (처치)
- sales: 매출 (결과)
S러너
S러너는 가장 기본적인 방법으로 단일 머신러닝 모델 $μ_s$를 사용하여 추정한다.

여기서 CATE 추정을 하기 위해선 결과 Y를 예측하려는 모델에 처치변수를 특성으로 포함하면 된다. 그러나, 이 모델은 처치효과를 직접 출력하지 않고 오히려 반사실 예측값을 구한다. 이는 다양한 처치에서의 예측이 가능하기에 처치가 이산형인 경우에도 해당 모델은 정상적으로 작동하며 실험군과 대조군의 차이가 CATE 추정값이 된다.
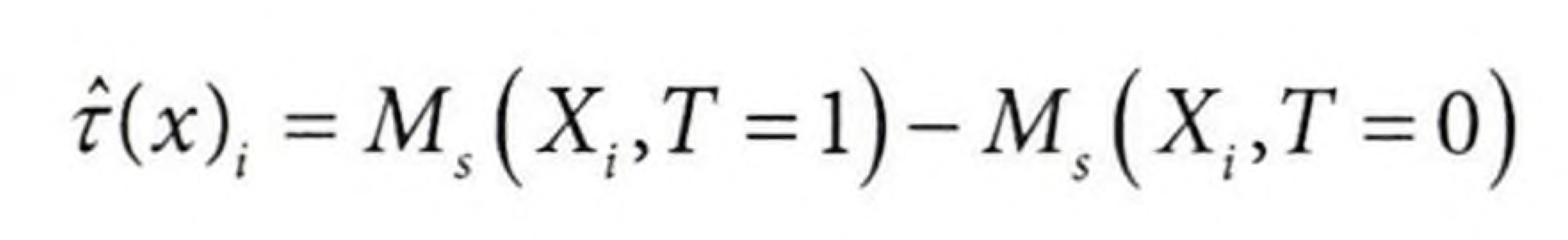
아래 다이어그램은 S러너를 설명한다. 여기서 러너는 특성 중 하나로 처치를 포함하는 머신러닝 모델이다.
처치가 연속형일 때에는 약간의 추가 작업이 필요하다. 먼저 처치의 그리드를 정의해야 한다.
- 예제에서는 처치(dicounts)가 0%부터 40%까지 변하므로, [0, 10, 20, 30, 40] 그리드를 사용할 수 있다.
- 예측하고자 하는 데이터를 확장하여 각 행이 그리드의 각 처칫값을 한 번씩 복사한다.
- 이를 수행하는 가장 쉬운 방법은 그리드의 값이 있는 데이터프레임을 예측하려는 데이터(test set)에 교차 조인하는 방법이다.
그 결과 데이터는 아래와 같다.

이번에 실험 대상(Day)에 대한 곡선을 그려서 어떤 모습인지 확인해보자. 아래 그래프를 통해 2018. 12. 25일에 추정된 반응 함수가 2018. 06. 18일보다 더 가파른 모습을 확인할 수 있다. (크리스마스 날에 할인에 더 민감)

우리가 구한 반사실 예측이 정확한지는 전혀 다른 문제로 여기서는 신경쓰지 않아도 된다. 예시에서는 아직 CATE 예측을 하지 않았기에 선형회귀를 통해 CATE 예측을 수행한 결과는 아래와 같다
CATE 예측값이 존재하기에 누적 이득 곡선을 사용하여 모델을 평가한 그래프는 아래와 같고 꽤 괜찮은 성능을 보여주는 것을 확인할 수 있다.

S러너는 랜덤화된 데이터가 많고 상대적으로 쉬운 데이터셋에 특화된 성능으로, 인과추론 문제에 처음 시도하기 좋은 모델이다. (이유는 다음과 같다.)
- S러너는 랜덤화된 데이터가 없어도 괜찮은 성능을 보이는 경향이 있다.
- S러너는 이진 & 연속형 처치에 모두 활용할 수 있다.
그러나 S러너의 단점도 존재한다. (이유는 다음과 같다.)
- 처치효과를 0으로 편향시키는 경향이 존재한다.
- S러너가 일반적으로 정규화 머신러닝 모델을 사용하기에 정규화가 추정된 처치효과 제한할 수 있다.
- 처치변수가 다른 공변량보다 결과를 설명하는 영향력이 작다면, S러너는 처치변수를 완전히 버릴 수 있다.
위의 문제들은 이중/편향 제거 머신러닝 또는 R러너로 해결한다.
이중/편향 제거 머신러닝
이중/편향 제거 머신러닝 or R러너는 FWL 정리의 정제된 버전으로 이해할 수 있다.
아래는 이중/편향 제거 머신러닝 모델에서 잘 사용되는 처리효과 추정 식이다. 여기서 $μ_y(X_i)$는 $E[Y|X]$를 추정하고 $μ_t(X_i)$는 $E[T|X]$를 추정한다.

머신러닝 모델은 데이터를 유연하게 학습하기에 FWL 스타일의 직교화를 유지한채 Y와 T의 잔차를 추정하면서 상호작용과 비선형성을 잘 포착할 수 있다. 관측되지 않은 교란 요인이 없다면 아래와 같은 직교화 과정으로 ATE를 구할 수 있다.

머신러닝을 사용하여 복잡한 함수의 형태를 포착할 수 있다는 장점이 있지만, 과적합을 유발할 수 있다.
이 문제의 해결책은 교차 예측과 아웃 오브 폴드 잔차에 있다. 모델을 적합시키는데 사용한 동일한 데이터셋에서 잔차를 구하는 대신, 데이터를 K개의 폴드로 분할하고 K-1개의 폴드에서 모델을 추정한 후 남겨진 폴드에서 잔차를 얻는다. 전체 데이터셋에 대한 잔차를 얻으려면 동일한 과정을 K번 반복한다. 이러면 모델이 과적합 되어도 잔차를 0으로 만들지는 않는다.
이중 머신러닝으로 CATE 추정
ATE에만 관심이 있다면, 결과의 잔차를 처치의 잔차에 회귀하면 된다고 하였다. 반면 CATE에 대한 예측값을 얻기 위해선 몇가지 조정이 필요하다.
우선 매개변수 τ가 실험 대상의 공변량에 따라 바뀌도록 한다.

$μ_y$와 $μ_t$는 특성 X에서의 결과와 처치를 예측한다. 이식을 재조정하여 오차에 관한 식으로 구성한다.

이 식을 인과 손실 함수로 인식할 수 있는데, 이 손실의 제곱을 최소화하면 원하는 CATE인 $τ(X_i)$의 기댓값을 추정할 수 있다.

이는 R러너가 최소화 하려는 손실이기에 R 손실이라고도 부른다. 이를 최소화하기 위해선 아래 수식을 이용하여 최소화한다. 이 식은 평균제곱오차를 계산할 때 사용한 식이다.
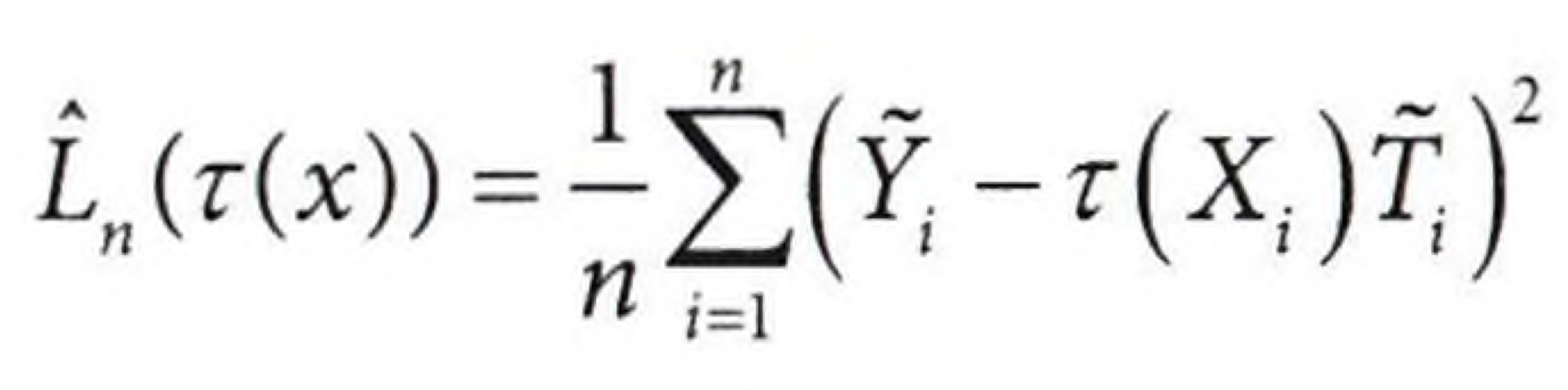

R러너의 장점은 CATE 추정값을 직접 출력한다는 것이다. 아래 누적 이득 곡선을 기준으로 CATE 순서를 매기는데 훌륭한 성능을 보인다는 것을 확인할 수 있다.

(이중 머신러닝에 대한 시각적인 직관은 생략한다.)
'Analytics' 카테고리의 다른 글
| [ML/DL] ResNet (feat: Skip-Connection) (1) | 2024.10.04 |
|---|---|
| [RecSys] 추천시스템 전반적 개요 정리 (3) | 2024.09.29 |
| [ML/DL] Transformer: Attention Is All You Need (2) | 2024.09.26 |
| [Causal Inference] 이질적 처치효과 (2) | 2024.09.24 |
| [Causal Inference] 성향점수 (5) | 2024.09.22 |