

오늘은 seq2seq을 간단히 리뷰해보고자 한다.
seq2seq 모델은 LSTM을 기본단위로 한다.
기계번역에서 LSTM이 RNN보다 성능이 좋았던 이유를 돌아보면, LSTM은 두개의 정보 흐름을 사용한다는 것에 차이가 있었음을 알 수 있다. 하나는 셀 상태(CtCt)라고 불리는 장기기억 정보이고 다른 하나는 히든 상태(HtHt)라고 불리는 단기기억 정보이다. LSTM은 이 두가지 정보를 사용하여 문장의 장기의존성 문제를 해결한다.

그러나 기계번역의 문제점은 장기의존성 문제 뿐만이 아니다.
기계번역의 가장 큰 문제점은 문장의 어순과 단어의 갯수가 불일치 한다는 것이다. 보는 바와 같이 해석되는 단어의 갯수와 해석하는 단어의 갯수가 일대일 대응하지 않기 때문에 번역에 있어서 어려움이 존재한다. seq2seq 모델은 이러한 문제를 해결한다.
seq2seq 모델이 어떻게 작동하는지 알아보자.
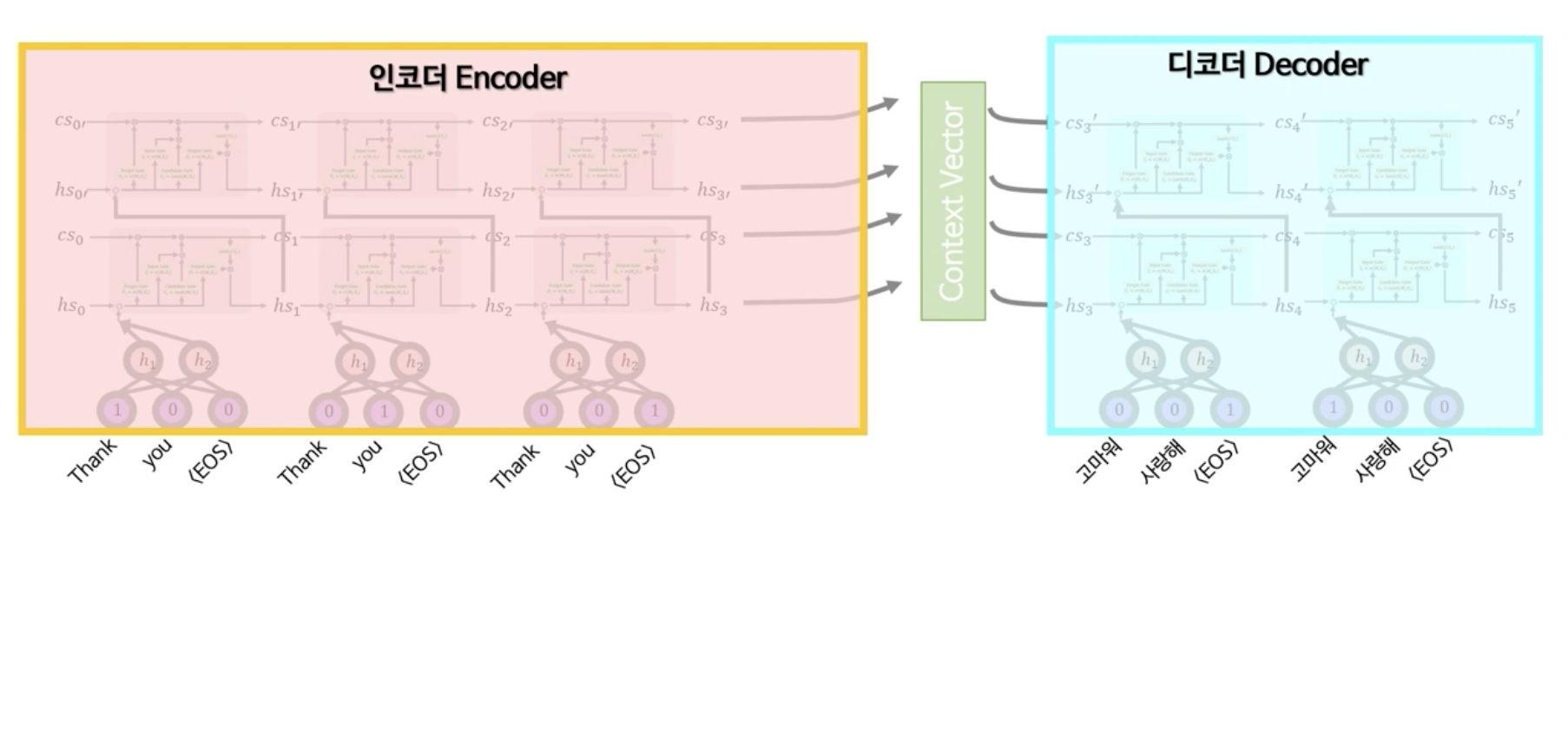
예를 들어 Thank you를 고마워 라고 번역하는 과정을 한번 살펴보자.
Thank라는 단어를 Word2Vec를 이용하여 LSTM으로 넣는다. 그러면 Thank가 LSTM의 순전파를 통해 cs1cs1과 hs1hs1을 생성해낸다.
그 다음 you를 앞선 (1)과 같이 Word2Vec을 이용하여 그 다음 LSTM에 입력한다. 그러면 cs1cs1과 hs1hs1의 you 단어는 새로운 cs2cs2와 hs2hs2를 생성해낸다.
그 후 마지막으로 영어의 문장이 끝났기 때문에, 문장 끝을 의미하는 <EOS>를 입력하여 cs3cs3와 hs3hs3를 생성한다.
위 과정을 순서대로 겪으면 마지막에 생성되는 cs3cs3와 hs3hs3는 단순한 장단기 기억이 아니라 문장에서 사용된 모든 단어들의 장기 기억과 단기 기억을 압축한 정보가 된다.
seq2seq은 이 cs3cs3와 hs3hs3를 합쳐 Context Vector로 명명한다.
LSTM은 앞선 예와 같이 하나의 층으로 사용할 수도 있고 아래의 사진과 같이 더 큰 context vector를 만들어내기 위해 두 개의 층으로 만들어 사용할 수 있다. 중요한 점은 두 번째 층에 있는 LSTM과 첫 번째 층에 있는 LSTM은 가중치와 편향이 완전히 다른 새로운 LSTM이라는 것이다. 그리고 이 부분을 seq2seq에서는 인코더(Encoder)라고 부른다.
다음으로 Context Vector를 통해 번역 작업을 하는 과정을 살펴보자. 번역도 마찬가지로 LSTM을 사용한다. 이 때 사용되는 LSTM과 Word2Vec은 인코더에서 사용한 LSTM과 가중치와 편향이 완전히 다른 새로운 LSTM을 인지하자.
Context Vector는 cs3cs3와 hs3hs3를 받고 동시의 문장 입력의 시작은 <EOS>로 시작한다.
그렇게 되면 LSTM은 cs4cs4와 hs4hs4를 출력하게 되는데, 이 hs4hs4를 Word2Vec의 디코더(Decoder) 부분이 받아서 계산한 뒤에 Word2Vec의 출력값을 Softmax 함수를 이용하여 확률로 변환하게 된다. Softmax의 출력값에 의해 확률값이 가장 큰 고마워가 LSTM의 출력이 된다.
그 후 이 출력값이 다시 LSTM의 입력값으로 쓰이게 되어 입력값 고마워가 EOS와 cs4cs4와 hs4hs4를 만나 새로운 cs5cs5와 hs5hs5를 생성한다.
아까와 똑같은 방식으로 Word2vec의 디코더 부분에 cs5cs5와 hs5hs5를 넣어 값을 계산하고 이를 softmax 함수에 넣어 값을 계산하게 되는데, 이 때 softmax의 출력값이 <EOS>가 되면 번역이 종료된다.
역전파 과정은 너무 복잡하기에 생략하지만, 대략적으로 그 과정은 아래와 같다.
Loss를 구하기 위해 아래와 같이 단어의 softmax 출력을 원-핫 벡터로 바꾼 뒤, 이 둘의 Loss를 Cross-Entropy Loss로 설정한 후, 계속해서 파라미터를 업데이트 해나아간다.
인코더와 마찬가지로 여기서도 두 개의 층으로 이루어진 LSTM이 가능하며, 이 부분이 바로 seq2seq의 디코더(Decoder) 부분이 된다.
결론적으로 최종적인 seq2seq의 형태를 Encoder - Context Vector - Decoder의 구조로 이해할 수 있다. 이러한 구조 덕분에 어순과 길이가 다른 여러가지의 언어를 번역할 수 있고 챗봇과 같은 대화 형태의 어플리케이션에서 활용될 수 있다.
Reference
https://www.youtube.com/watch?v=qwfLTwesx6k&t=339s
'Analytics' 카테고리의 다른 글
| [Causal Inference] 인과추론 기초 & 무작위 실험 (16) | 2024.09.16 |
|---|---|
| [ML/DL] Seq2Seq with Attention (0) | 2024.09.02 |
| [보충 리뷰] SHAP (3) | 2024.08.28 |
| [논문 리뷰] SHAP (1) | 2024.08.26 |
| [논문 리뷰] Prophet 시계열 예측 (0) | 2024.08.20 |